
目录
华伦.巴菲特 Warren E. Buffett 是全世界有史以来,靠股票赚最多钱的人,1956年回到奥玛哈以100美元起家,至1999年8月为止,个人资产总额已达360亿美元以上,成为全美第二富有的人。巴菲特的投资法则非常简单,首先不理会股价每日的涨跌,其次,不去担心总体经济情势的变化;再者,以买下一家公司的心态投资而非投资股票,而其方法中有四大原则:
本文章使用 Mac OS 并以 Jupyter Notebook 作为编辑器
import tejapi import pandas as pd import numpy as np
Note: tejapi 安装以命令提示字元 (Windows)/终端机 (Mac),输入 pip install tejapi
tejapi.ApiConfig.api_key = 'Your Key' tejapi.ApiConfig.ignoretz = True
loc 」、「分群 groupby 」、「枢纽 pivot_table 」由于巴菲特的原则中,部份是无法量化的,因此只选取可数量化的原则,其原则背后的原理皆为,公司能帮股东赚钱的能力高,方法如下:
set_1set_2set_3set_4set_5set_6我们选择 2019/12/31 符合条件的股票,在 2020/1/1 买入并持有至 2020/12/31。每个一条件都会做一个 set ,最后取交集得到符合条件的标的。
比较每一元保留盈余是否创造超过一元的市场价值时,由于牵涉到公司上市年限是否够久,故筛选2020还活著的公司,且上市时间大于7年公司,并去除银行证券业,因为依据 ROE 公式,可以靠举债来提升,所以在负债比例高的产业(如: 银行业28、金控业30)则不适合用 ROE 来判断。
Step 1. 搜寻上市日的资料库
tejapi.search_table("上市日")
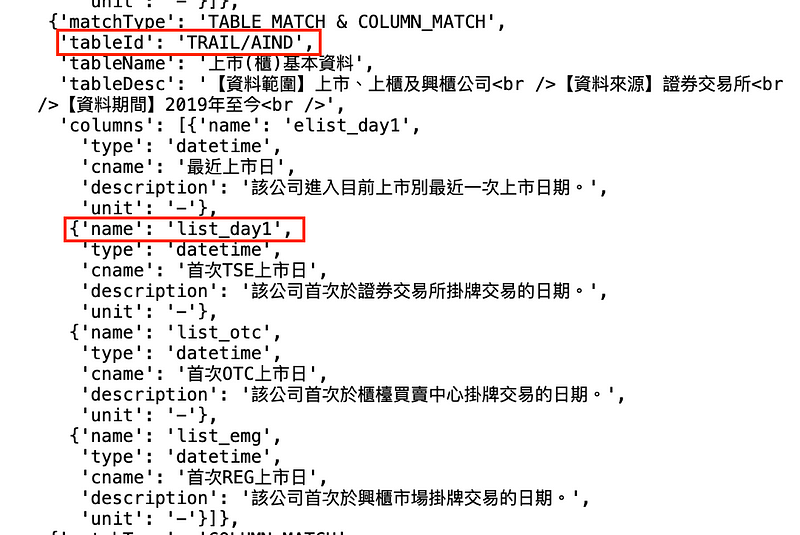
Step 2. 依据搜寻结果,我们使用 TWN/AIND 资料库,并选择上市日早于 2013 ,且去除产业 28、29。
comp_data = tejapi.get('TWN/AIND',
elist_day1 ={'lt':'2013-01-01'},
ind = {'ne':('28', '30')},
mkt = 'TSE',
opts = {'columns':['coid', 'elist_day1',
'ind']},
chinese_column_name=True,
paginate=True
)
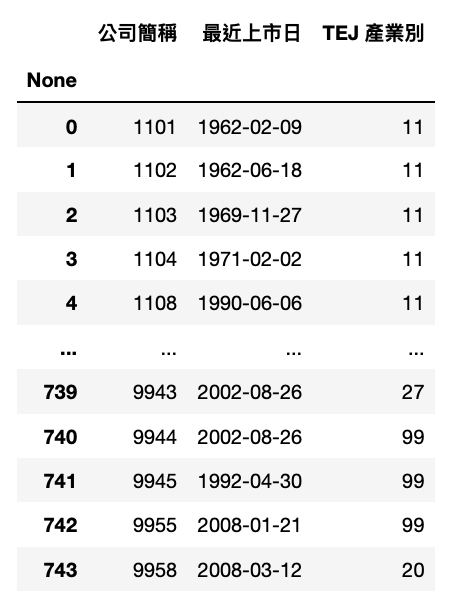
取得符合条件的公司列表,用于之后制作产业平均的数据
comp_list = list(comp_data['公司简称'])
Step 3. 制作产业群组字典
将股票池有的产业全部列出并转成为 list
industry_list = comp_data["TEJ 产业别"].unique().tolist()
将产业内所有公司,制作产业 ROE 字典 dict
industry_data = tejapi.get('TWN/AIND',
ind = industry_list,
mkt = 'TSE',
opts = {'columns':['coid', 'ind']},
chinese_column_name=True,
paginate=True
).reset_index(drop=True)
将资料库转换成 key 产业别,value 为公司列表
industry_dict = {}
for i in industry_list:
industry_dict[i] = industry_data[industry_data['TEJ 产业别'] ==
i]['公司简称'].tolist()
例如要查询产业 13 的所有公司
industry_dict["13"]

后续的选股方法都与此类似,故在这段会加以著墨,内容会较为复杂,读者遇到不理解的部分可以先查看完整程式码。
Step 1. 个股 ROE(A)-税后
ROE_data = tejapi.get('TWN/AIM1A',
coid = comp_list,
mdate= '2019-12-01',
opts={'pivot':True,
'columns':['coid', 'mdate', 'R103']},
chinese_column_name=True,
paginate=True)
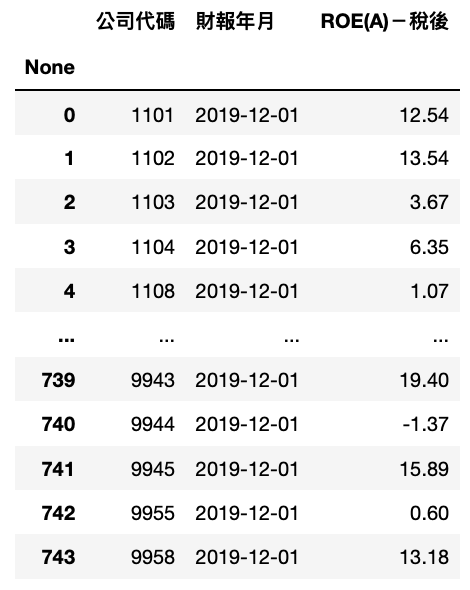
Step 2. 迭代产业别转换成字典,制作产业 2019 平均 ROE 字典
industry_roe = {}
for i in industry_list:
data = tejapi.get('TWN/AIM1A',
coid = industry_dict[i],
mdate='2019-12-01',
opts={'pivot':True,
'columns':['coid', 'mdate', 'R103']},
chinese_column_name=True,
paginate=True).reset_index(drop=True)
industry_roe[i] = data.groupby('公司代码').mean().mean()[0]
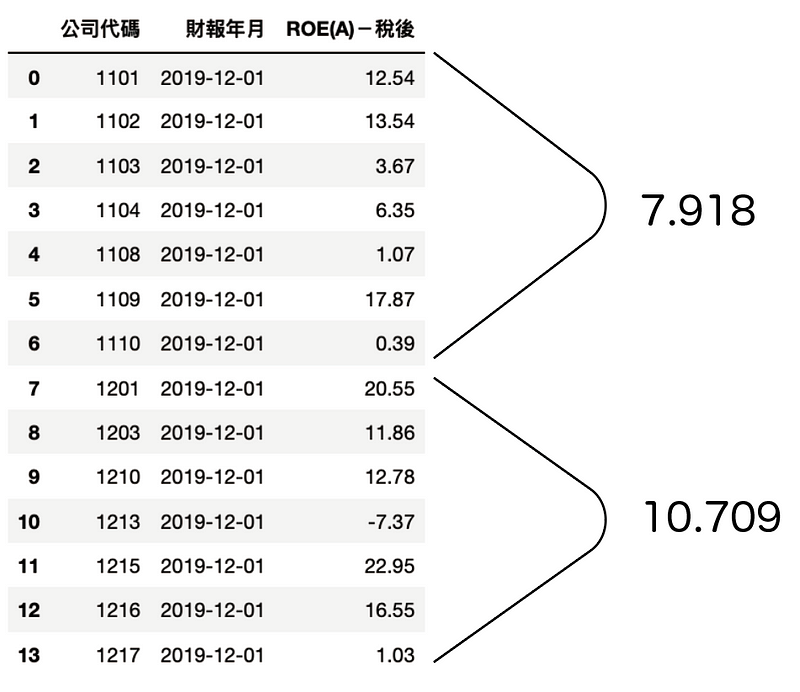

Step 3. 将产业别对应上述的字典,替换成产业平均 ROE
ROE_data['产业净值报酬%'] = ROE_data['TEJ 产业别'].apply(lambda x: industry_roe[x])
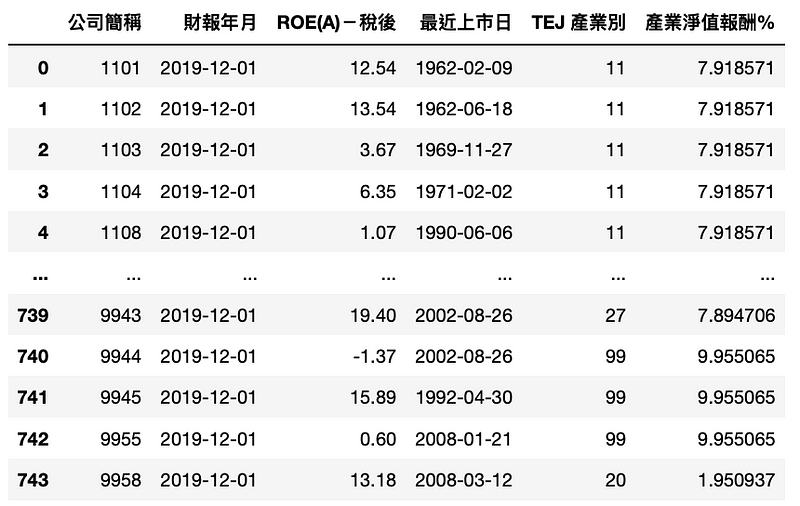
Step 5. 符合条件的公司储存到 set_1
set_1 = set(ROE_data[ROE_data['ROE(A)-税后'] > ROE_data['产业净值报酬%']]['公司简称'])
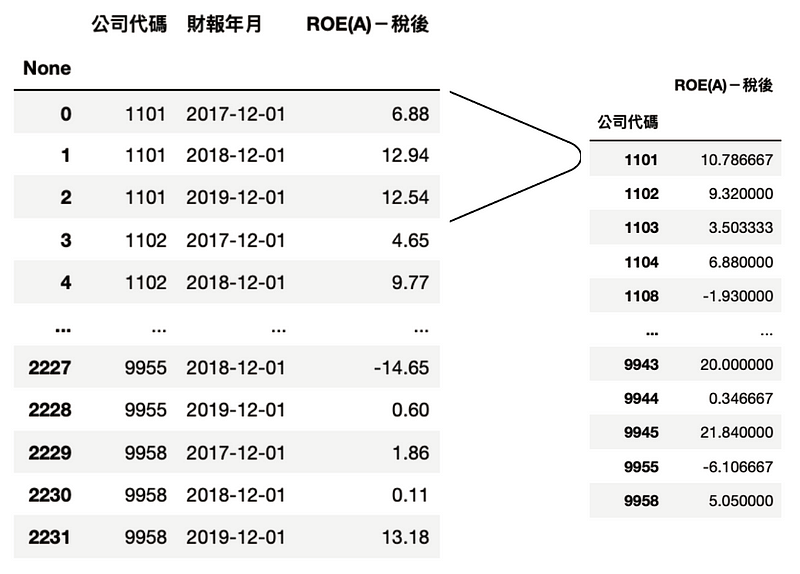
选取三个年度的资料,操作方法如同第一点的公司分组 groupby,数值做平均 mean 并将资料存进 set_2
ROE_data_3Y = tejapi.get('TWN/AIM1A',
coid=comp_list,
mdate=['2017-12-01','2018-12-01','2019-12-
01'],
opts={'pivot':True,
'columns':['coid', 'mdate', 'R103']},
paginate=True,
chinese_column_name=True,
)
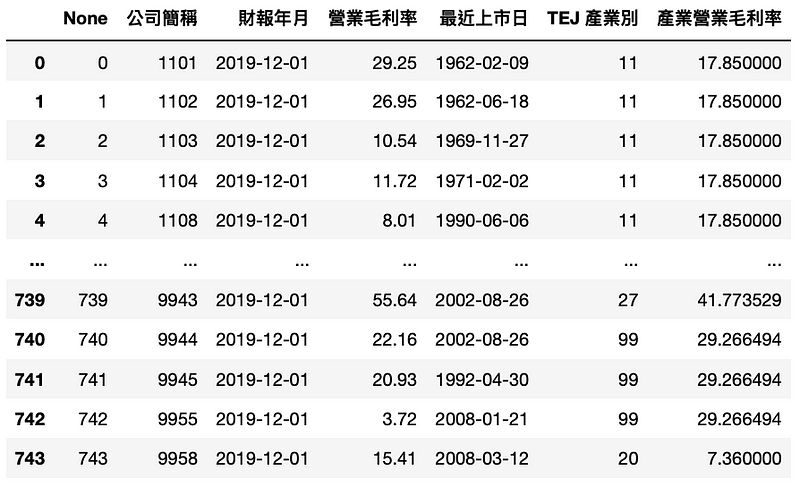
操作方法同第一点,完整程式码请详见此连结,并将资料存进 set_3
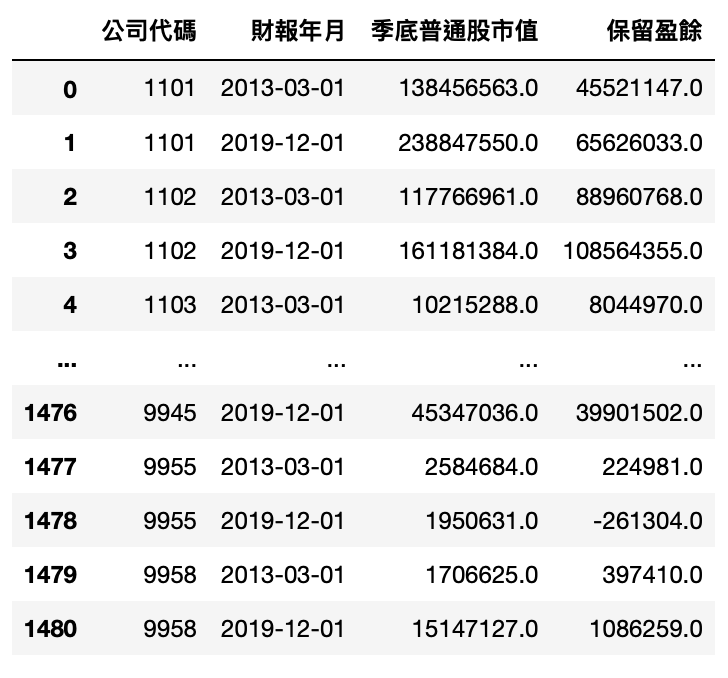
Step 1. 获得市值、保留盈余资料
MV_RE_data = tejapi.get('TWN/AIM1A',
coid = comp_list,
mdate= ['2019/12/01','2013/03/01'],
opts={'pivot':True,
'columns':['coid', 'mdate','MV','2341']},
chinese_column_name=True,
paginate=True
).reset_index(drop=True)
Step 2. 将资料转置 pivot_table
MV_RE_data.pivot_table(index='公司代码', columns='财报年月').reset_index()
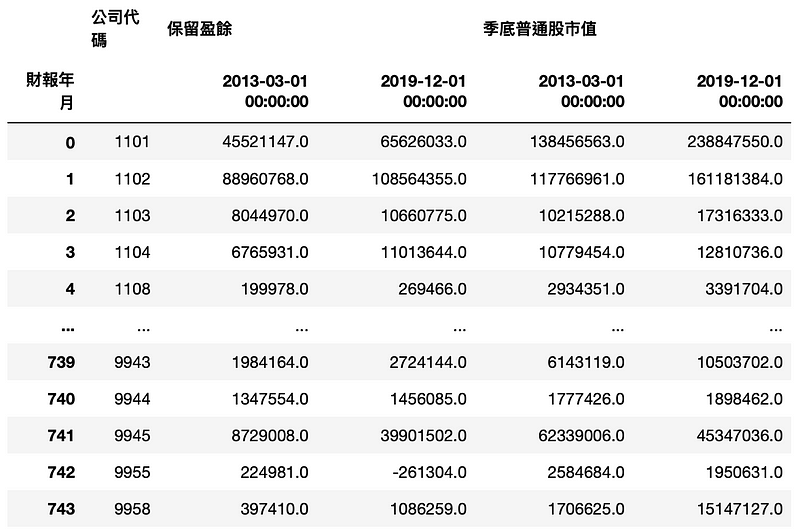
Step 3. 再将两个栏位相减即可得到增加值
MV_RE_data['保留盈余增加值'] = MV_RE_data.iloc[:,2] - MV_RE_data.iloc[:,1]
MV_RE_data['市值增加值'] = MV_RE_data.iloc[:,4] - MV_RE_data.iloc[:,3]
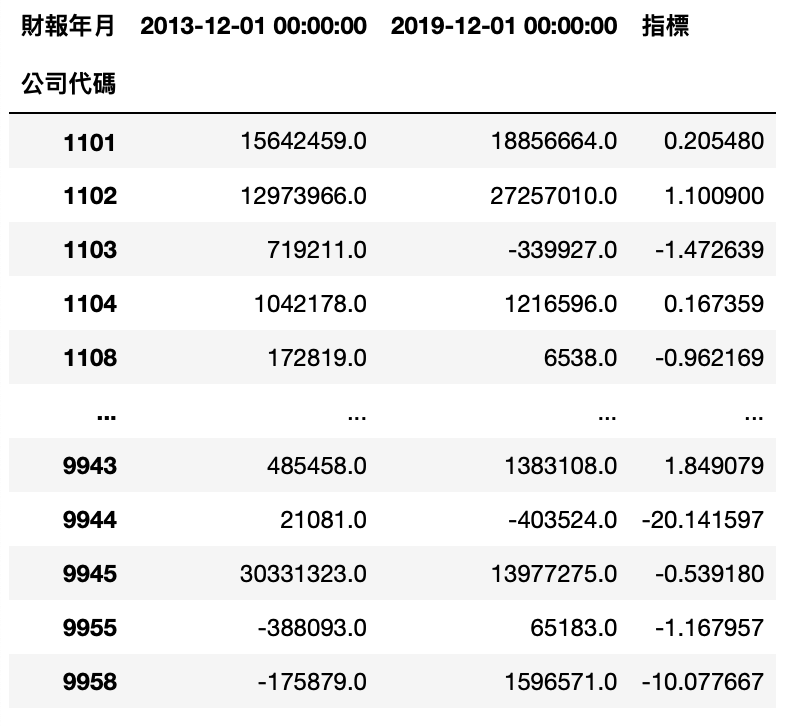
Step 4.计算指标
MV_RE_data['指标'] = MV_RE_data['市值增加值'] / MV_RE_data['保留盈余增加值']
Step 5. 将符合条件的股票存到 set_4
set_4 = set(MV_RE_data[MV_RE_data['指标']>1]['公司代码'])
Step 1. 获得自由现金流量资料
cash_data = tejapi.get('TWN/AIM1A',
coid= comp_list,
mdate=['2013-12-01', '2019-12-01'],
opts={'pivot':True,
'columns':['coid', 'mdate', 'R69B']},
paginate=True,
chinese_column_name=True,
)
Step 2. 操作方法如第四点资料枢纽转置,栏位相减获得指标
Step 3. 储存到 set_5
set_5 = set(cash_data[cash_data['指标'] > 1].index)
numpy_financial其模组说明文件点此连结,在终端机输入 pip install numpy_financialimport numpy_financial as npf
这里举一个例子,某公司的四年现金流量为 100 / -150 / -200 / 400,我们要计算他的净现值可以利用 NPV 法,使用贴现率 10% 和未来各期支出(负值) 和收入(正值) 来计算投资的净现值
cash_flows = np.array([100, -150, -200, 400]) npf.npv(0.1, cash_flows)
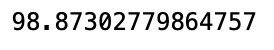
def Cashflows(y0):
y1 = y0 * 1.15
y2 = y1 * 1.15
y3 = y2 * 1.15
y4 = y3 * 1.05
y5 = y4 * 1.05
y6 = y5 * 1.05
y7 = y6 * 1.05
y8 = y7 * 1.05
y9 = y8 * 1.05
y10 = y9 * 1.05
cashflows = np.array([y1,y2,y3,y4,y5,y6,y7,y8,y9,y10])
return cashflows
Step 1. 获取 2019 年度自由现金流量资料和市值
MV_cash_data = tejapi.get('TWN/AIM1A',
coid= comp_list,
mdate='2019-12-01',
opts={'pivot':True,
'columns':['coid', 'mdate', 'R69B',
'MV']},
paginate=True,
chinese_column_name=True,
).reset_index(drop=True)
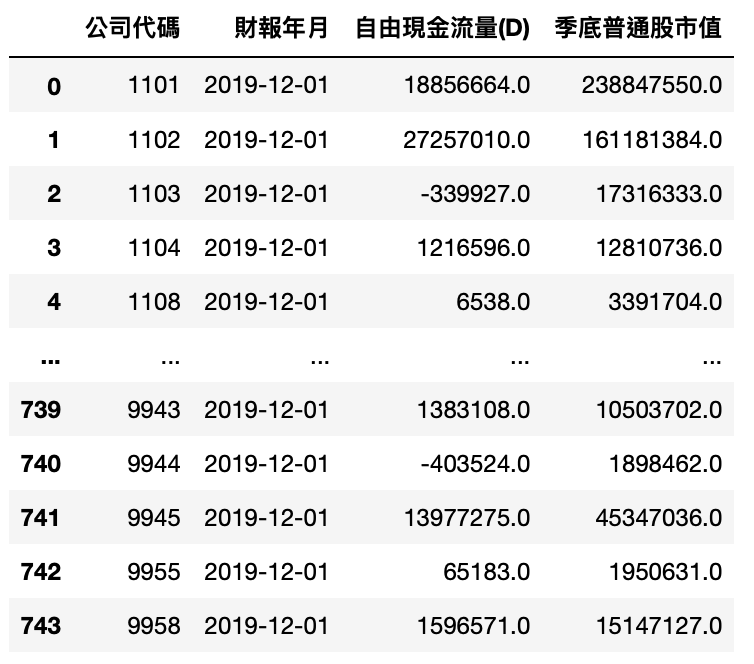
Step 2. 现金流转换成现值
MV_cash_data['自由现金流量(D)'].apply(lambda x: npf.npv(0.09, Cashflows(x)))
Step 3. 计算指标
MV_cash_data['指标'] = MV_cash_data['季底普通股市值'] / MV_cash_data['自由现金流量(D)'].apply(lambda x: npf.npv(0.09, Cashflows(x)))
Step 3. 符合条件的股票储存为 set_6
set_6 = set(MV_cash_data[(MV_cash_data['指标']<1) & (MV_cash_data['指标']>0)]['公司代码'])
来到我们最期待的最后阶段,将各个 set 取交集获得我们的投资组合
set_1 & set_2 & set_3 & set_4 & set_5 & set_6
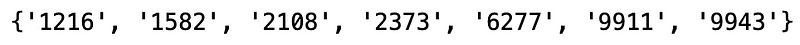
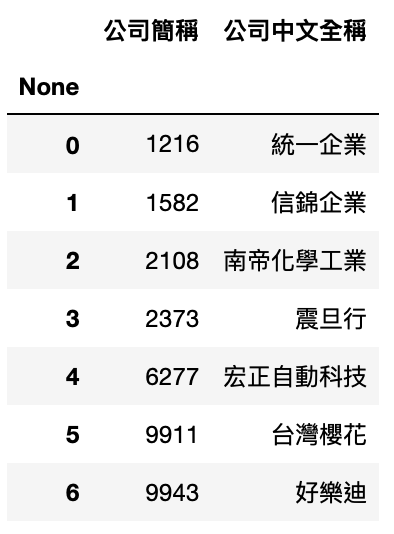
参考 模组化回测系统 ,我们将此投组代入系统,由于投资组合的价格落差过大,我们采用等权重买入持有,2020 获得的报酬率%为
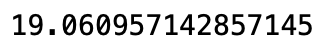
如果能熟练的操作资料库,股票的筛选设计可以非常客制化,也可以去实测坊间各式各样的选股策略,而此篇的内容较为复杂,需多花点心力研读,若读者有兴趣制作更多选股策略,可以前往我们的官方网站,里面有提供更多财务、交易等财金资料,来帮助您制作更好的选股策略!
本文仅供参考之用,并不构成要约、招揽或邀请、诱使、任何不论种类或形式之申述或订立任何建议及推荐,读者务请运用个人独立思考能力,自行作出投资决定,如因相关建议招致损失,概与作者无涉。
