
目录
随机森林简单来说,就是由多颗决策树所组成,其为使用 Bagging 加上随机特征采样所产生的一种演算法。因为是基于 CART演算法,所以可以处理类别资料与连续资料,其他的优点像是其能够接收高维度的资料、对杂讯容忍度高、拟和结果准确率高等等,故亦时常用于Kaggle等商业竞赛。
本文将利用财务数据作为特征,来预测下一季的股价是上涨还是下跌,因此为一种二元分类问题。接著再观察是否能从模型结果得出有用的资讯来进一步优化我们的选股策略!
本文使用 Windows OS 并以 Jupyter Notebook 作为编辑器
#功能模组import pandas as pdimport numpy as npimport matplotlib.pyplot as plt#机器学习from sklearn.ensemble import RandomForestClassifier#TEJ APIimport tejapitejapi.ApiConfig.api_key = 'Your Key'tejapi.ApiConfig.ignoretz = True
Step 1. 捞取产业代码、财务、报酬率资料
security = tejapi.get('TWN/ANPRCSTD',mkt = 'TSE',stypenm = '普通股',paginate = True,chinese_column_name = True)#储存公司代码security_list = security['证券码'].tolist()#储存产业代码industry_code = security[['证券码', 'TSE业别']]industry_code = industry_code.set_index('证券码').to_dict()['TSE业别']
首先捞取的是上市普通股的资料,这边我们需要的是公司代码,以及其所对应的产业代码,因此将其转为字典储存。
groups = []while True:if len(security_list) >= 50:groups.append(security_list[:50])security_list = security_list[50:]elif 0 <= len(security_list) < 50:groups.append(security_list)break
将公司以50家为一组,以便下一步进行回圈捞取资料。这么做的目的是避免到时捞资料时一次捞取过多,而导致捞取失败的情况。
fin_data = pd.DataFrame() #财务资料ret_data = pd.DataFrame() #报酬率资料date_data = pd.DataFrame() #日期资料for group in groups:fin_data = fin_data.append(tejapi.get('TWN/EWIFINQ',coid = group,chinese_column_name = True,paginate = True)).reset_index(drop=True)ret_data = ret_data.append(tejapi.get('TWN/APRCD2',coid = group,opts = {'columns': ['coid', 'mdate', 'roi_q']},paginate = True,chinese_column_name = True)).reset_index(drop=True)date_data = date_data.append(tejapi.get('TWN/EWFINDATE2',coid = group,opts = {'columns': ['coid', 'mdate', 'fin_date']},paginate = True,chinese_column_name = True)).reset_index(drop=True)
透过回圈的方式一次取得每组公司所有年度的财务资料、季报酬率资料。值得注意的是,这边的季报酬率为日频率资料,因为其代表的是当日的前一季累积的报酬率,为滚动式季报酬的概念,因此每日都会有一笔资料。date_data则为TEJ提供的交易日、财报公布日对应的表格,非常适合用于合并股价与财务资料。
Step 2. 资料合并
date_data = date_data.groupby(['证券码', '财务公告日']).last().reset_index()date_data = date_data.rename(columns = {'交易日期':'年月日', '财务公告日':'财报发布日'})
取得下一次财报公布前的最后一笔交易日期,接著会利用此日期与季报酬率资料的日期进行合并,则此季报酬代表的即是财报公布日后的整季报酬率。最后再改变栏名以利后续合并
merge = date_data.merge(fin_data, on = ['证券码', '财报发布日'])merge = merge.rename(columns = {'证券码':'证券代码'})merge = merge.merge(ret_data, on = ['证券代码', '年月日'])merge = merge.set_index(['证券代码', '财务资料日']).select_dtypes(include=np.number)
合并所有的资料,将证券代码、财务资料日作为新的索引,且只选择数值资料的栏位
Step 1. 切割训练集与测试集,并进行模型训练
condition = merge.index.get_level_values('财务资料日') < '2020'train_data = merge[condition].fillna(0)test_data = merge[~condition].fillna(0)rf = RandomForestClassifier(n_estimators=100, criterion= 'entropy')rf.fit(train_data.drop(columns = '季报酬率 %'), train_data['季报酬率 %'] > 0)
这边我们以2020年以前的资料作为训练集,以后的资料为测试集,并将缺失值都补上零,最后将测试集的特征、标签资料(布林值)丢到模型开始训练。
Step 2. 模型表现
print("训练集分数: " , rf.score(train_data.drop(columns = '季报酬率 %'), train_data['季报酬率 %'] > 0))print("训练集分数: " , rf.score(test_data.drop(columns = '季报酬率 %'), test_data['季报酬率 %'] > 0))

selected = rf.predict(test_data.drop(columns = '季报酬率 %'))test_data[selected]
以模型预测出的布林值作为筛选条件,挑选并观察 2020年以后被模型预测下季报酬率为正的资料
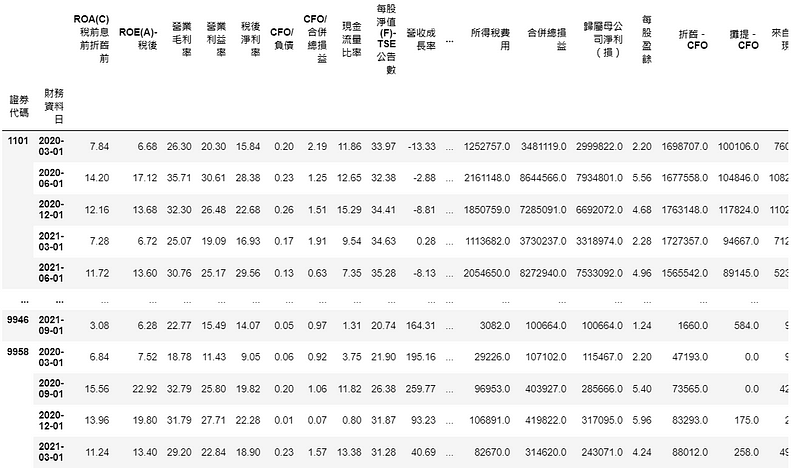
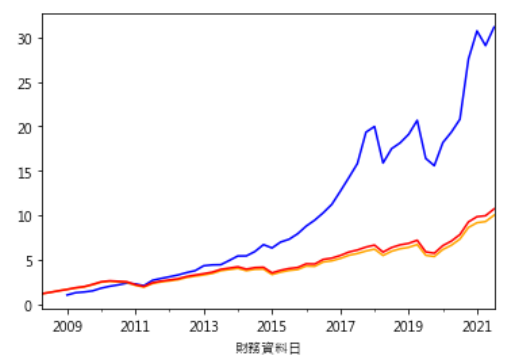
plt.rcParams['font.sans-serif'] = ['Microsoft JhengHei'] #显示中文(test_data[selected].groupby('财务资料日').mean()['季报酬率 %']*0.01 + 1).cumprod().plot(color = 'blue') #randomforest(test_data[~selected].groupby('财务资料日').mean()['季报酬率 %']*0.01 + 1).cumprod().plot(color = 'orange') #benchmark1(test_data.groupby('财务资料日').mean()['季报酬率 %']*0.01 + 1).cumprod().plot(color = 'red') #benchmark2
这边划出三条线,蓝线为每季模型预测上涨的股票,形成的投组累积报酬率;橘线为反向筛选出的报酬率;红线为不进行筛选的报酬率。可以看到模型预测的选股表现相较之下较佳。
Step 1. 挑选重要特征
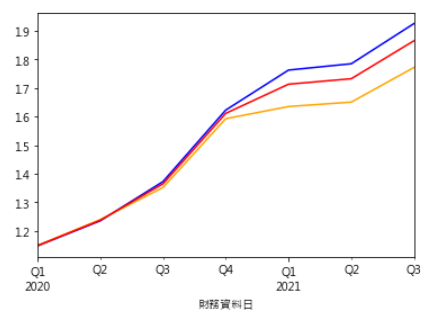
feature_name = train_data.columns[:-1]important = pd.Series(rf.feature_importances_, index = feature_name).sort_values(ascending=False)important.head(20)
观察前20重要的特征,当作我们选股的依据
positive_features = ['营业利益成长率', '营收成长率', '投资活动之现金流量', '营业毛利成长率', 'ROE(A)-税后', '营业外收入及支出', 'ROA(C) 税前息前折旧前', 'CFO/合并总损益', '税后净利率', '每股净值(F)-TSE公告数', '营业利益率', '营业毛利率', '来自营运之现金流量']接著从这20个重要特征中,主观选出值越大、理应越为正面的几个数据或指标,因为之后要将这些值转成百分位数,并计算一个总分作为筛选标准,所以高分必须意味著表现越良好。
Step 2. 同产业相比设定
merge['产业'] = merge.index.get_level_values('证券代码').map(industry_code)merge = merge.reset_index().set_index(['证券代码', '产业', '财务资料日'])
这边将资料处理当时储存的 industry_code字典的值,也就是产业代码映射到 merge 里并形成新栏位,再将此栏位与证券码、财务资料日一起当作索引
Step 3. 计算重要特征总分,以此作为选股依据
score = merge[positive_features].groupby(['财务资料日', '产业']).rank(pct=True).sum(axis = 1)rank = score.rank(pct = True) #总分再rankfilters = rank > 0.97(merge[filters].groupby('财务资料日').mean()['季报酬率 %']*0.01+1).cumprod().plot(color = 'blue')(merge[~filters].groupby('财务资料日').mean()['季报酬率 %']*0.01+1).cumprod().plot(color = 'orange')(merge.groupby('财务资料日').mean()['季报酬率 %']*0.01 + 1).cumprod().plot(color = 'red')
将资料以同期同产业分组,再以rank(pct=True) 在组内进行每个特征的百分位数排名,接著横向加总后再排名一次。最后筛选出分数高于 97 百分位的所有资料,并进行全年度的回测。以下可以看到这种选股策略(蓝线),显著优于其他 benchmark 表现。
this_season = fin_data[fin_data['财务资料日'] == '2021-09-01']this_season['产业'] = this_season['证券码'].map(industry_code)this_season = this_season.set_index(['证券码', '财务资料日', '产业']).loc[:,positive_features]score = this_season.groupby(['产业']).rank(pct=True).sum(axis = 1)rank = score.rank(pct = True)firm_list = [i[0] for i in rank[rank > 0.97].index]firms = tejapi.get('TWN/AIND',coid = firm_list,opts = {'columns':['coid','fnamec']},paginate = True,chinese_column_name = True)
这边直接选择 2021 Q3,选股逻辑一样是挑选该期间同产业最好的前3%,再利用 TWN/AIND 资料库观察公司名称
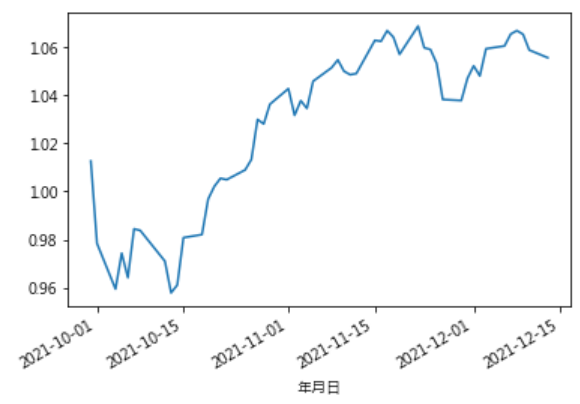
ret_sofar = tejapi.get('TWN/APRCD2',coid = firm_list,mdate = {'gte':'2021-09-30'},opts = {'columns': ['coid', 'mdate', 'roia']},paginate = True,chinese_column_name = True)ret_sofar.groupby('年月日')['日报酬率 %'].mean().apply(lambda x: 0.01*x + 1).cumprod().plot()
各产业优质公司投组从2021 Q3结束以来的累积报酬率
因为 TEJ API 资料库资料较为齐全,所以在资料处理上较为轻松,只要将资料合并、分割训练集后即可开始建立模型。虽然模型预测成功率仅 54.88 %,但我们仍然可以从这个模型去观察哪些特征是判断报酬率涨跌的重要因素。读者们可以试著调整模型参数、选择不同特征、利用 TEJ API 各种资料库,筛选出个股后再参考各产业未来趋势进行二次筛选等等,最后再去建构一个报酬率表现最佳的投组,并观察未来是否能够持续这种表现。
本文仅供参考之用,并不构成要约、招揽或邀请、诱使、任何不论种类或形式之申述或订立任何建议及推荐,读者务请运用个人独立思考能力,自行作出投资决定,如因相关建议招致损失,概与作者无涉。
