
目录
预测股票一直是人们所追求的,然而股票的随机性远远难以掌握,在资料科学的进步下,计算成本大幅降低,本文用使用相较于【量化分析】预测市场?! 更复杂的深度学习模型,进行股票预测,使用前10天的开盘价、最高价、最低价、收盘价、成交量,预测隔天的收盘价。
本文使用 Google colab作为编辑器
###三宝
import numpy as np import pandas as pd import matplotlib.pyplot as plt
import tejapi
tejapi.ApiConfig.api_key=###yourkey
##################
import tensorflow as tf from keras.layers.core import Dense, Dropout, Activation from keras.callbacks import EarlyStopping,ModelCheckpoint from keras.models import Sequential from keras.layers import LSTM from sklearn.preprocessing import MinMaxScaler
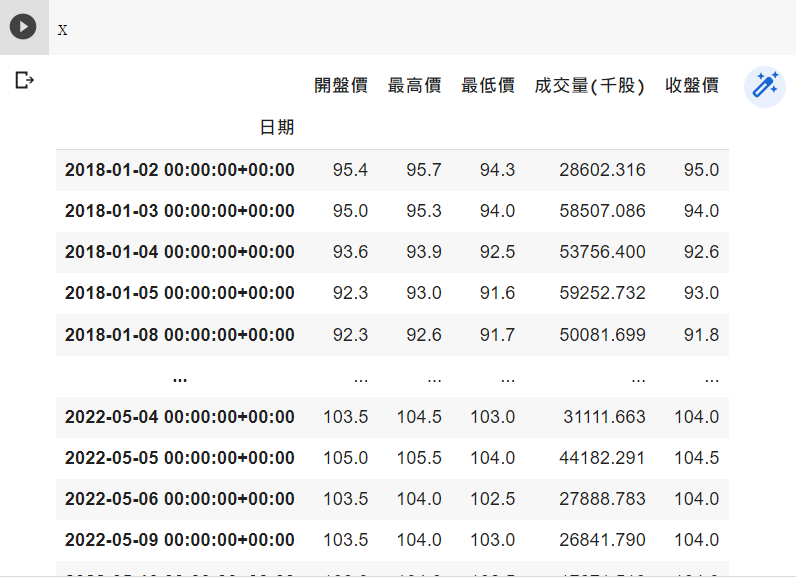
证券交易资料表:上市(柜)未调整股价(日),资料代码为(TWN/EWPRCD)。
建立RMSE 来评估模型预测能力
以及将资料转换成符合LSTM输入的形式型态如下图所示分别代表为
(batch_size,time_steps,seq_len) : 1163组,5天,5个变数

dataset : 输入训练资料
target : 预测资料
start_index : 起始点 通常为0 因为后续自己会分组
end_index : 终点 设0
history_size 输入长度 本文选10 target_size 预测长度 本文选1
def root_mean_squared_error(y_true, y_pred):
return np.sqrt(np.mean(np.square(y_pred - y_true)
###计算Rmse
def multivariate_data(dataset, target, start_index, end_index, history_size,
target_size, single_step=False):
data = []
labels = []
start_index = start_index + history_size
if end_index is None:
end_index = len(dataset) - target_size
for i in range(start_index, end_index):
indices = range(i-history_size, i)
data.append(dataset[indices])
if single_step:
labels.append(target[i+target_size])
else:
labels.append(target[i:i+target_size])
return np.array(data), np.array(labels)
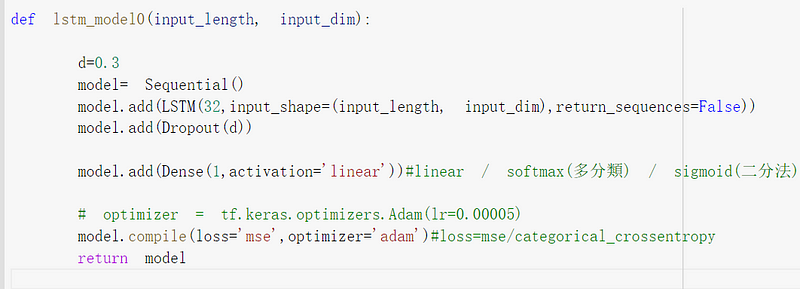
接下来是来叠模型了,其中Dropout是用来防止过拟,本文就不详尽解释原理,可以从d去调整从0~1之间,
input length为输入的时间长度,本文选用10天
input_dim为变数数量,本文总共有5个变数
return_sequences : True 为维持 (batch ,time_steps ,seq_len) ,连接下一层LSTM 设置 False 将会变成一维
loss 使用mean_squared_error训练,Optimizer 使用 Adam
def build_model(input_length, input_dim):
d=0.3
model= Sequential()
model.add(LSTM(128,input_shape=(input_length, input_dim),return_sequences=True))
model.add(Dropout(d))
model.add(LSTM(64,input_shape=(input_length, input_dim),return_sequences=False))
model.add(Dropout(d))
model.add(Dense(1,activation='linear'))
#linear / softmax(多分类) / sigmoid(二分法)
model.compile(loss='mse',optimizer='adam')
return mode1
coid='3037'
start='2016-01-01'
end='2022-5-22'
opts={'columns': ['open_d' ,'high_d','low_d','mdate', 'volume','close_d']}
tw=tejapi.get('TWN/EWPRCD',coid=coid,
mdate={'gt':start,'lt':end},
paginate=True,
chinese_column_name=True,
opts=opts
)
tw.set_index("日期",drop=True,inplace=True)
tw.sort_index(inplace=True)
设置 变数 与应变数 收盘价为要预测的,其他为变数
y =tw["收盘价"] x =tw
scaler=MinMaxScaler(feature_range=(0,1)) y=scaler.fit_transform(y.to_frame()) scaler1=MinMaxScaler(feature_range=(0,1)) x=scaler1.fit_transform(x)
并将资料分成训练组,验证组,测试组
x,y=multivariate_data( x ,y , 0 ,None, 10 , 1 ,single_step=True) split =0.95 x_,y_ = x[0:int(split*len(x))] , y[0:int(split*len(x))] x_test ,y_test = x[int(split*len(x)):] , y[int(split*len(x)):] split= 0.8 x_train,y_train =x_[:int(split*len(x_))] , y_[:int(split*len(x_))] x_vaild,y_vaild =x_[int(split*len(x_)):] , y_[int(split*len(x_)):]


my_callbacks = [
tf.keras.callbacks.EarlyStopping(patience=300, monitor = 'val_loss')
] ######## 在训练组训练,使用验证组选取
filepath="lstm.best.hdf5"
checkpoint = ModelCheckpoint(filepath, monitor='val_loss', verbose=1, mode='min',save_best_only=True)
call_backlist = [my_callbacks,checkpoint]
lstm00 = lstm_model0(10,5)
historylstm0 = lstm0.fit( x_train, y_train, batch_size=30,shuffle=False , epochs=1000,validation_data=(x_vaild,y_vaild),callbacks=call_backlist)
lstm00.summary()
EarlyStopping : 在训练组训练参数,以验证组最低为选择标准,如果300个epochs,没有改善即停止训练
filepath : 模型储存路径
ModelCheckpoint : 选择val_loss最低的当作最后的模型
batch 是每次训练抽取样本数
epochs 训练次数
shuffle True 随机打乱 False 不打乱排序
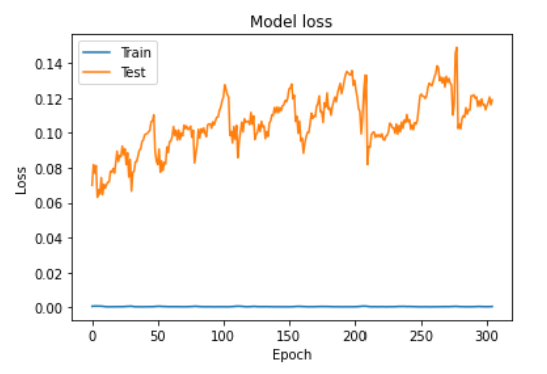
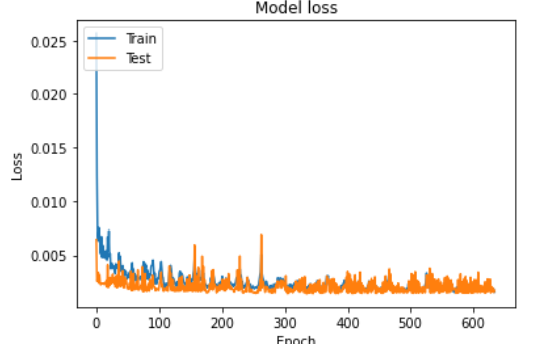
#绘制 训练情形
plt.plot(historylstm0.history['loss'])
plt.plot(historylstm0.history['val_loss'])
plt.title('Model loss')
plt.ylabel('Loss')
plt.xlabel('Epoch')
plt.legend(['Train', 'Test'], loc='upper left')
plt.show()
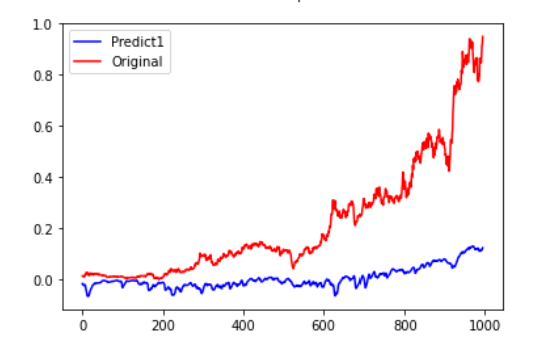
lstm0train = lstm00.predict(x_train) lstm0val = lstm00.predict(x_vaild) lstm0pre = lstm00.predict(x_test)
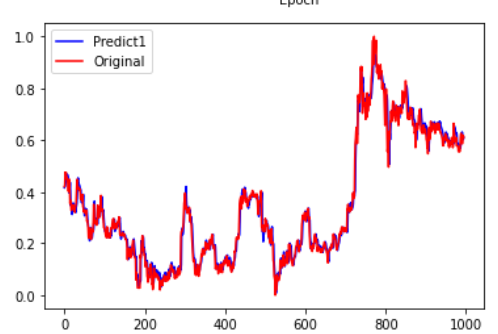
pre = lstm00.predict(x_train) pre1=lstm00.predict(x_vaild) fc=np.concatenate((pre,pre1)) yreal=np.concatenate((y_train,y_vaild)) plt.figure(facecolor='white') pd.Series(fc.reshape(-1)).plot(color='blue', label='Predict1') pd.Series(yreal.reshape(-1)).plot(color='red', label='Original') plt.legend() plt.show()
lstm0pre= scaler.inverse_transform(lstm0pre)#将资料转换回来 y_test = scaler.inverse_transform(y_test.reshape(-1,1))
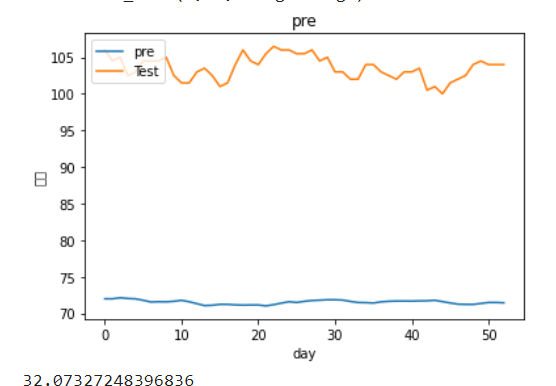
plt.figure()
plt.plot(lstm0pre)
plt.plot(y_test)
plt.title('pre')
plt.ylabel('股价')
plt.xlabel('day')
plt.legend(['pre', 'Test'], loc='upper left')
plt.show()
root_mean_squared_error(lstm0pre,y_test)

接下来尝试2层的
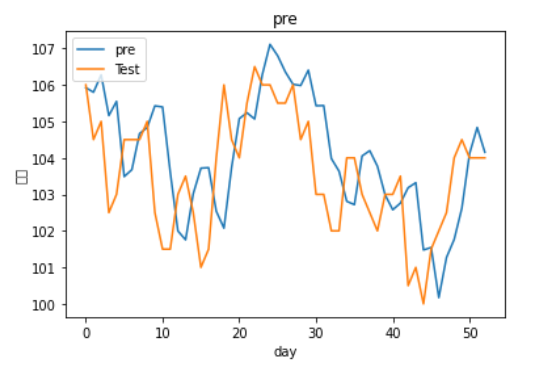

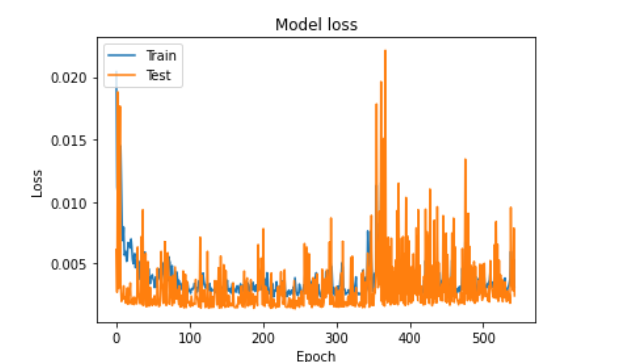
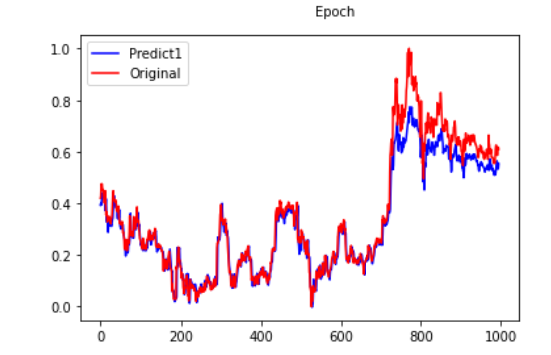
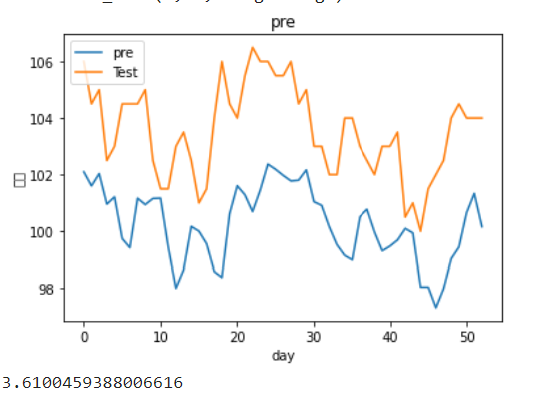
我们能看到虽然在stack-Lstm下拟和效果不错,但实际观察过后,发现模型的预测仅仅是把昨天去预测明天,也就是使用深度学习单纯预测隔天收盘价也是不太可行的,或许需要改成预测涨跌,以及加入更多特征看是否能改善预测能力! 也许能结合之前转写的一些选股策略再将资料喂入,以后会再为大家介绍!
