
目录
近来演算法兴起,发展出各式各样的数学模型用以分析并解决问题,经典的演算法为「回归模型」,但随著科技的进步,发展出能自我改进学习的算法 — 机器学习(Machine Learning),发展至今成为最火热的类累神经网路模型 (Deep Learning)。
本文章介绍树状模型 XGBoost,文章将会分两部分,上半段为环境设定与模组安装,以及资料库的介绍。下半段为资料的预处理,模型的训练、预测和视觉化。
先来介绍当今火红的的演算法 XGBoost,所谓的 Boosting 就是一种将许多弱学习器集合起来,变成一个更强大的学习器,对于最终预测结果都有更高的准确度。
XGBoost ( Extreme Gradient Boosting ),是一种拟合残差的梯度下降算法 Gradient Boosted Tree (GBDT),每一步学习是基于之前的错误中进步,并会保留原本的模型,并加入新的函数,作为修正上次学习的错误,此为集合多个弱学习器。应用方面主要解决监督式学习,可以处理分类也可以解决回归问题。
本文使用 Mac OS 并以 Jupyter Notebook 作为编辑器
由于 XGBoost 使用到众多的模组,如果版本不一致会产生报不完的错误。我们可以建立新的环境来安装这些模组,安装的方式有很多种方法,本安装为较为简单易懂的方式,以求发生最少错误。

Anaconda 可以说是初学者的懒人包,解决目前各系统的不一致导致安装困难的状况,拥众多爱好者及企业用户外,整理了超过1000种的 Packages可安装,适用于 Windows、Linux 和 MacOS 不同作业系统环境,也具虚拟环境管理器,对于在安装、执行机器学习环境上变得简单快速
Windows 系统的话可以点 Anaconda Prompt
输入建立环境指令
conda create -n 新环境名称 python==3.8
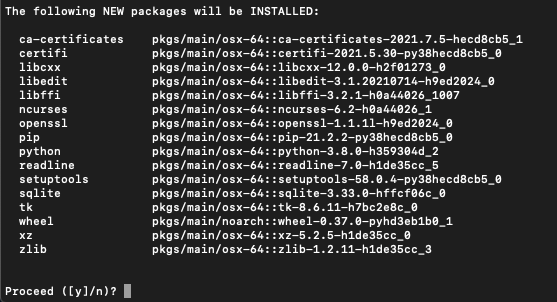
会跳出问你是否安装,输入 y 再按 enter 就成功了!我们新环境名称范例为 test,当然也可以输入你喜欢的名称
conda env list
我们可以输入以上指令,查看目前我们有哪些的虚拟环境,确认一下有建立成功
conda activate 新环境名称
此时终端机最前面括号 (base) 就会变成我们刚刚建立新环境的名称 (test),代表启动成功
如果之后安装失败,要重新安装,我们只要简单的输入一串指令就可以移除新创的环境,再重新安装一次,完全不用担心影响其他的环境
conda env remove -n 新环境名称
conda activate 新环境名称
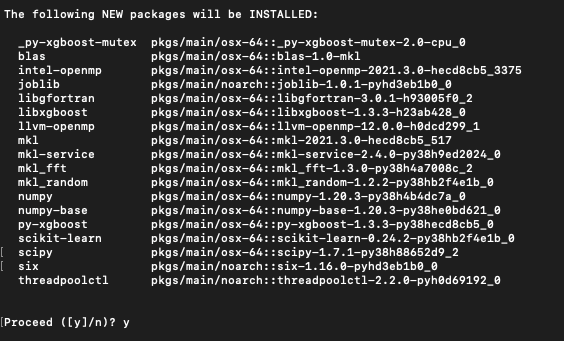
conda install py-xgboost
一样会询问是否要安装这些模组,输入 y 再按 enter 就开始安装了,跑完就成功啦!是不是非常简单!
Homebrew 我们可以理解为一种安装方式,例如 python 的模组安装是使用 pip ,而在 macOS,Homebrew 就是最被广为使用的套件管理工具。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"在终端机上输入上串指令以安装
brew install graphviz
以上就是我们这次文章主要会用到的模组了!不过在新环境里,XGBoost 没有部份我们需要的模组,就得另外安装一下,各模组中间用空格隔开
pip install pandas matplotlib tejapi
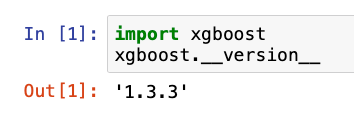
最后赶快在 jupyter 检视是否成功安装!
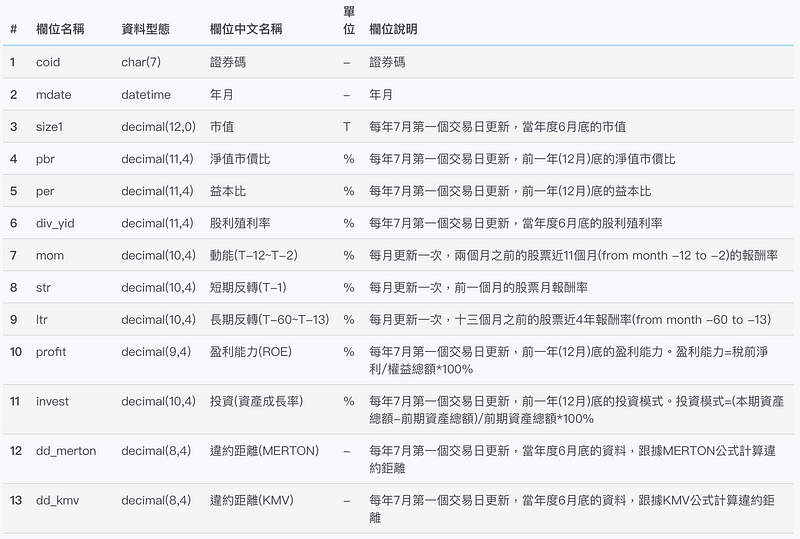
本文章将使用 台湾_多因子DB(TWN/AFF_RAW) 里面所提供的交易因子,作为演算法需的变数,此资料库参考 Kenneth R. French 网页及 2000 年以来于财金前三大期刊 (JF、RFS、JFE) 发表的重要且有用投资因子,将各学者衡量因子的指标,利用台湾市场资料计算好,以月频率方式将所有指标的资料整理好。
df = tejapi.get('TWN/AFF_RAW',
coid = '9921',
mdate={'gte': '2015-01-01', 'lte':'2020-12-31'}
chinese_column_name = True,
paginate = True)
本文章上半部分为讲解模组安装,相信大部分的人在一开始接触程式时,一定会到许多安装上的状况,装来装去还是没办法成功,最后电脑要整台重灌,因此环境的安排也是一个重要的课题喔!在大家都成功安装后,文章下半部分会开始使用资料库,处理数据,把资料喂给模型,最后得出我们要的预测值,作为我们投资的参考。
