目录
员工流动率是指企业在一定时期内因员工的离职和新进而发生的人力资源变动情况。这个指标是衡量企业组织和员工队伍稳定性的重要概念。较低的员工流动率表示公司的人事变动相对较少,反映出企业内部的稳定性和持续性。相反,较高的员工流动率可能暗示著组织问题、工作不满意度或其他因素,可能对企业运营和工作氛围产生负面影响。监控员工流动率能够帮助企业了解和评估其人力资源管理策略的有效性,并采取相应的措施来提高员工保留和满意度,确保组织的长期稳定和发展,而预测员工流动率使企业能够更好地规划和管理人力资源,降低成本,提高人才保留率,并促进组织效能的提升。
本文使用 MacOS 作业系统以及 Jupyter Notebook 作为编辑器
# 载入所需套件
import pandas as pd
import numpy as np
import tejapi
from collections import Counter
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
import statsmodels.regression.linear_model as sm
import matplotlib.pyplot as plt
# 登入TEJ API
api_key = 'YOUR_KEY'
tejapi.ApiConfig.api_key = api_key
tejapi.ApiConfig.ignoretz = True本次实作使用的栏位如下,请注意 violate_times 并不是原本资料表中的栏位,是经过前处理后产生的栏位。
gte, lte = '2021-01-01', '2021-12-31'
TR = tejapi.get('TWN/ACSR01A',
paginate = True,
mdate = {'gte':gte, 'lte':lte},
)
gte, lte = '2020-01-01', '2021-01-01'
ED = tejapi.get('TWN/AXEMPA',
paginate = True,
mdate = {'gte':gte, 'lte':lte},
)
gte, lte = '2020-01-01', '2021-01-01'
LAW = tejapi.get('TWN/ACSR20A',
paginate = True,
mdate = {'gte':gte, 'lte':lte},
)
gte, lte = '2021-01-01', '2021-12-31'
TWSE = tejapi.get('TWN/ACSR19A',
paginate = True,
mdate = {'gte':gte, 'lte':lte},
)我们筛选教育程度、TWSE 公司治理评鉴资料表中所需要的栏位,并计算违反劳动基准法次数。接著,由于TWSE 公司治理评鉴资料表中的公司代码为数字会导致合并错误,因此要先转换成字串型态。
ED = ED[["coid", "apct", "bpct" ,"cpct", "dpct", "epct", "fpct" , "emp_sum"]]
LAW = pd.DataFrame(data = [Counter(LAW["coid"]).keys(), Counter(LAW["coid"]).values()]).T.rename(columns = {0:"coid", 1:"violate_times"})
TWSE = TWSE[["coid", "rating"]]
TWSE["coid"] = TWSE["coid"].astype(str)df_main = TR
for i in [ED, TWSE, LAW]:
df_main = pd.merge(df_main, i, on = "coid")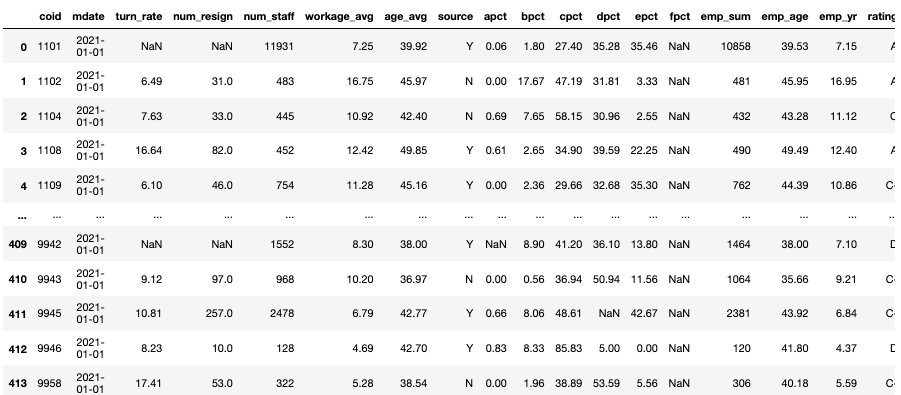
由于资料表中有空值,会导致无法训练回归模型,但请注意,将空值补 0 并不一定是最好的方法,空值应该要如何填补根据数据资料、预期结果的不同有许多处理方法,由于此次实作著重的点是模型建立,因此我们将空值补 0 以利计算。
接著,我们将治理评鉴等级由字串型态转换为数值型态以符合回归分析模型的输入。
dataset_regression = df_main[df_main["turn_rate"].notna()].drop(columns = ["source", "fpct"])
dataset_regression["rating"].unique()
trans = {
"A+":"7",
"A":"6",
"B":"5",
"C":"4",
"C-":"3",
"D":"2",
"D-":"1",
"NA":"0",
}
dataset_regression["rating"] = dataset_regression["rating"].apply(lambda x : trans.get(x))
dataset_regression = dataset_regression.fillna(0)X = dataset_regression.iloc[:, 3:].values
y = dataset_regression.iloc[:, 2].values我们将资料以 8 : 2 的比例切分成训练集与测试集,并且设定 random_state 以保证每次模型执行结果不变。
将测试集放入模型后,我们把实际值与模型预测值拿出来比较。
x_train, x_test, y_train, y_test= train_test_split(X, y, test_size=0.8, random_state=42)
regressor = LinearRegression()#创建一个名为regressor的物件
regressor.fit(x_train, y_train)#训练线性归模型
y_pred = regressor.predict(x_test)
print(y_pred.shape)#y_pred 为一维向量
np.set_printoptions(precision = 2)#显示两位小数
P_vs_T = np.concatenate((y_pred.reshape(len(y_pred),1),y_test.reshape(len(y_test),1)),1)
print(P_vs_T)
#将y_pred与y_test分别转为len(y_pred),1)的2维阵列后合并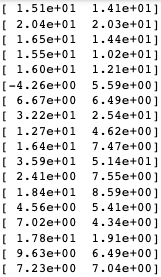
透过观察数值,可以发现有部分预测数值误差不小,甚至有负数的情况,为了清楚了解数值预测结果到底准不准确,我们使用长条图方便理解,并定义当预测值与实际值相差超过 2% 时,判定为预测失准。
classification = [1 if abs(x-y)>1 else 0 for x,y in P_vs_T ]
print(Counter(classification))
plt.bar(x = [0,1], height = Counter(classification).values(),tick_label=["False", "True"] )
plt.show()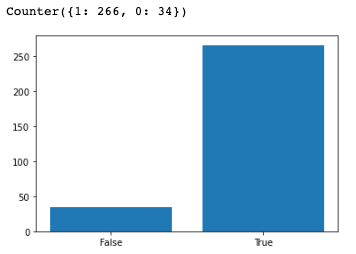
然而透过图表我们可以发现模型的结果整体上还是不错的,拥有 88% 的准确率。
#输出模型截距与系数
print(regressor.fit(x_train,y_train).intercept_)
print(regressor.fit(x_train,y_train).coef_)
反向淘汰法是一种特征选择的方法,用于从模型中排除对目标变量没有显著影响的特征。它通过逐步剔除变量,从最初的全模型开始,每次移除对模型效能影响最小的特征,直到剩下的特征达到一定的标准(例如显著性水平,一般来说是当 p-value 小于 0.05 时)。这种方法可防止过度拟合和降低模型复杂度,同时提高模型的解释性和预测能力。反向淘汰在多元线性回归中被广泛应用,以筛选出对目标变量最具影响力的特征。
而为何标准会是 p-value < 0.05 ,这就要讲到统计学中的假设检定。
假设检定(Hypothesis testing)是统计学中的一种方法,用于对关于母体参数的假设进行统计推论。在假设检定中,我们提出两个对立的假设,分别是「虚无假设」(null hypothesis)和「对立假设」(alternative hypothesis)。通常,虚无假设表示无效、没有差异或没有关联,而对立假设则表示有效、有差异或有关联。
透过收集样本数据并进行统计分析,我们使用检定统计量来评估这些数据对于虚无假设的支持或反驳。通过计算检定统计量的值并将其与预先设定的显著性水平进行比较,我们可以进行结果的统计判断。如果检定统计量的值极端地偏离了虚无假设,我们可能拒绝虚无假设,并提出对立假设。否则,我们则无法拒绝虚无假设。
而 p-value 表示获得观察结果或更极端结果的概率,假设虚无假设为真。当p-value小于预先设定的显著性水平(通常为0.05)时,我们可以拒绝虚无假设。这是因为小于0.05的 p-value 表示观察到的结果非常罕见,根据虚无假设的假设条件,我们无法轻易获得这样极端的结果。因此,拒绝虚无假设意味著我们有足够的证据支持对立假设的成立。
然而,值得注意的是,0.05 只是一个通常使用的显著性水平。在某些情况下,根据研究的特性或问题的严重性,可以选择更严格的显著性水平(例如0.01)。此外,应该综合考虑其他因素,如样本大小、研究设计和效应大小等,来做出适当的统计判断和解释结果。拒绝虚无假设只是统计推论的一部分,需要谨慎地解释和报告结果,避免过度解读或误导性的结论。
我们透过 for 回圈来逐步剔除参数,并且保留准确率最高的模型资讯。
# 加上常数1以符合回归模型 y = b0+b1*X+b2*X^2+b3*X^3...
x_train = np.append(arr = np.ones((len(x_train[:,1]),1)).astype(int), values = x_train, axis = 1)
# back elimination
col = [0,1,2,3,4,5,6,7,8,9,10,11,12,13]
R_square = []
for i in range(len(col)):
x_opt=np.array(x_train[:,col], dtype=float)
regressor_OLS=sm.OLS(endog=y_train, exog= x_opt).fit()
R_square.append(regressor_OLS.rsquared)
if regressor_OLS.rsquared == max(R_square):
summary = regressor_OLS.summary()
attribute = col.copy()
P = regressor_OLS.pvalues.tolist()
print(col)
col.pop(P.index(max(P)))

我们将每次淘汰参数后的 r-squared 值以折线图呈现,r-squared 是一个统计量,用于评估回归模型对因变量变异性的解释程度。它表示因变量的变异百分比可以由独立变量(自变量)在模型中解释。r-squared 值的范围从 0 到 1 ,越接近 1 表示模型能够更好地解释因变量的变异性,而越接近0则表示模型的解释能力较弱。具体来说,r-squared 为 0 意味著模型无法解释因变量的变异性,而 r-squared 为 1 则表示模型完全解释了因变量的变异性。
plt.plot(R_square,'ro--', linewidth=2, markersize=6)
plt.xticks(ticks = [i for i in range(0,14)], labels= [i for i in range(1,15)][::-1])
plt.title("change in R_square")
plt.xlabel('number of attribute')
plt.ylabel('R_square')
plt.show()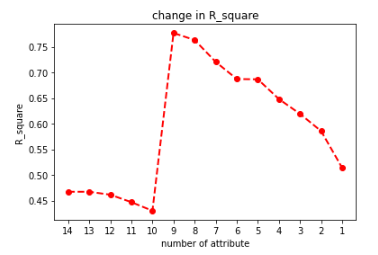
我们撷取 r-squared 最高时的参数并将对应的栏位名称打印出来。
col_map = dict(zip([0,1,2,3,4,5,6,7,8,9,10,11,], dataset_regression.iloc[:, 3:].columns))
print(attribute)
print(list(map(lambda x:col_map.get(x), attribute)))
查看 r-squared 最高时的统计讯息。
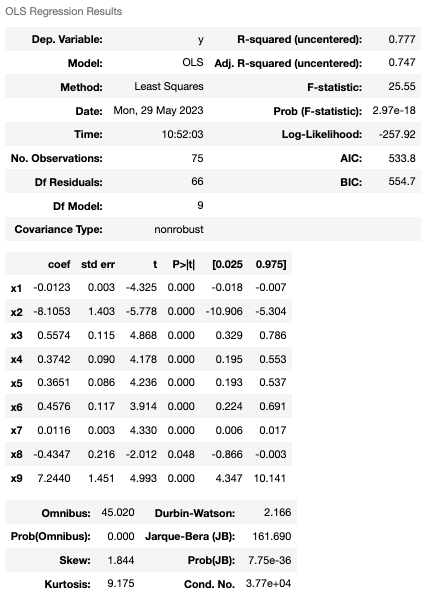
透果反向淘汰,我们成功地将模型准确由一开始的 46% 提升至 77%,并且通过分析参数组成,可以发现公司员工流动率主要是受到公司员工的年资、薪水及大学以下教育程度人数比例影响。然而,这些结论都只是基于统计原理的解释,r-squared 的解释应该与具体情况和模型的特点相结合。它可以帮助评估模型的适合度和预测能力,以及比较不同模型之间的优劣。因此,需要谨慎使用 r-squared,并结合其他评估指标和专业判断进行综合分析,以充分理解模型的解释能力和限制。
