
目录
幸存者偏差(Survivorship bias)是指在研究或观察中,只有成功或幸存下来的事物或个体被考虑,而那些失败或消失的事物或个体被忽略或排除在外的一种误差。这种偏差可能导致对整体情况的误解,因为仅仅观察到成功或幸存下来的事物可能并不代表整个群体的特征或真实情况。
幸存者偏差通常出现在样本选取、研究设计或回顾性分析等情境中。一个典型的例子是二战期间对飞机防御加强的研究。当时研究人员主要观察到返回基地的飞机上的损伤情况,然后根据这些观察结果提出防御建议。然而,这种观察忽略了那些被击落且无法返回的飞机,因此得出的结论可能并不适用于整个飞机群体。
幸存者偏差在选股时也可能产生影响,在选股过程中,投资者倾向于关注那些表现出色且获利的股票,而忽略那些表现不佳或失败的股票。这种观察只看到成功股票的例子,导致对整个市场或股票群体的情况产生了偏差。
幸存者偏差会使投资者误以为那些表现出色的股票具有普遍性或代表性,并认为它们的成功是由于特定的因素或策略所导致。投资者可能倾向于追逐这些成功股票,而忽略了市场风险、行业趋势和其他重要的选股因素。本次实作将使用简单的交易策略来具体说明何谓幸存者偏差。
本文使用Mac OS并以jupyter作为编辑器
import pandas as pd
import numpy as np
import tejapi
api_key = 'your_api_key'
tejapi.ApiConfig.api_key = api_key
tejapi.ApiConfig.ignoretz = True资料期间从 2020–01–01 至 2022–12–31,以生技医疗类股作为实例,抓取股价资讯作为分析资料。
comp_data = tejapi.get('TWN/ANPRCSTD',
paginate = True,
opts = {"columns":["coid", "mdate", "mkt", "stype", "list_date", "delis_date", "tseind"]}
)
#取得生技医疗类股代号,类别代码为22
coid_lst = list(comp_data.loc[(comp_data["stype"] == "STOCK") & (comp_data["tseind"] == "22")]["coid"])
gte, lte = "2020-01-01", "2022-12-31"
price_data = tejapi.get('TWN/AAPRCDA',
paginate = True,
coid = coid_lst,
mdate = {"gte":gte, "lte":lte},
opts = {"columns":["coid", "mdate", "fld014", "cls60", "close_d"]}
)证券属性资料表中显示了当前标的状态是否为下市柜,而上市(柜)调整股价(日)-均价资料表则包含了所有曾经上市柜公司的股价资讯,为了取得两张资料表中共有的股票代号,我们首先将上市(柜)调整股价(日)-均价资料表中的股票代码型态转换为字串,在使用set取得交集,并以此结果来过滤股价资料。
price_data["coid"] = price_data["coid"].astype(str)
inter_coid = list(set(coid_lst).intersection(set(price_data["coid"].unique())))
price_data[price_data["coid"].isin(inter_coid)]
本次实作我们取用最简单的均线回测,将短期均线与长期均线进行比较,当短期均线向上突破长期均线时,称为「黄金交叉」,视为买进的讯号。而当短期均线向下突破长期均线时,则称为「死亡交叉」,视为卖出的讯号。为求计算方便,本交易策略每当触发交易讯号时,除非该笔价格为标的价格资讯的最后一笔,也就是最后一天才会执行平仓,否则皆只会交易一单位的股票。本次实作以 10 日均线作为短期均线,60日均线作为长期均线。
首先,我们将股价资料依照股票代码进行分组。
fltr_price_data = price_data[price_data["coid"].isin(inter_coid)]
group = fltr_price_data.groupby("coid")接著定义均线交易策略的函式,该函式最终会返回两项资料,第一是交易历程的资料表,其中包含交易日期、标的代号、买入/卖出标示、交易股价、交易单位、剩余现金及持有部位,第二是交易结束后剩余的现金量。
def MA_strategy(df, principal):
position = 0
lst = []
for i in range(len(df)):
if df["fld014"].iloc[i] > df["cls60"].iloc[i] and principal >= float(df["close_d"].iloc[i])*1*1000:
principal -= float(df["close_d"].iloc[i])*1*1000
position += 1
lst.append({
"日期": df["mdate"].iloc[i],
"标的": df["coid"].iloc[i],
"买入/卖出": "买入",
"单价": float(df["close_d"].iloc[i]),
"单位": 1,
"剩余现金": principal,
"部位" : position
})
elif df["fld014"].iloc[i] < df["cls60"].iloc[i] and position > 0:
principal += float(df["close_d"].iloc[i])*1*1000
position -= 1
lst.append({
"日期": df["mdate"].iloc[i],
"标的": df["coid"].iloc[i],
"买入/卖出": "卖出",
"单价": float(df["close_d"].iloc[i]),
"单位": 1,
"剩余现金": principal,
"部位" : position
})
elif i == len(df)-1 and position > 0:
principal += float(df["close_d"].iloc[i])*position*1000
position -= position
lst.append({
"日期": df["mdate"].iloc[i],
"标的": df["coid"].iloc[i],
"买入/卖出": "卖出",
"单价": float(df["close_d"].iloc[i]),
"单位": position,
"剩余现金": principal,
"部位" : position
})
df_output = pd.DataFrame(lst)
return (df_output, principal)由于本次实作主要目的是为了显示股市中存在幸存者偏差,因此在本次交易策略上并不执著于完全符合现实层面的操作及配置,而是将整个交易策略作为自变数、投资组合设定为控制变数、所反应的投资报酬率为应变数,在这里我们给定每只标的都拥有相同的本金,并设定本金为 100 万元。
我们将在 2020–01–01 至 2022–12–31所有曾经存在的医疗生技业上市柜公司作为投资组合
print(f'2020–01–01 至 2022–12–31状态曾经为上市柜的公司数量:{len(list(comp_data.loc[(comp_data["coid"].isin(inter_coid))]["coid"]))}')
principal = 1000000
total_return_1 = 0
df = pd.DataFrame(columns = ["日期", "标的", "买入/卖出", "单价", "单位", "剩余现金", "部位"])
for g in group.groups.keys():
reuslt = MA_strategy(group.get_group(g), principal)
total_return_1 += round(reuslt[1], 2)
df = pd.concat([df, reuslt[0]], ignore_index=True)接下来进行 ROI 计算,将每档标的的最终剩余现金加总,除以初始金额,也就是 100 万 * 投组标的数量。
total_return = (total_return_1/(1000000*len(group.groups.keys())) - 1) *100
print(f"ROI : {total_return}%")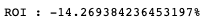
计算结果总绩效为 -14 %,接著剔除在 2020–01–01 至 2022–12–31之间下市柜的九家公司。在证券属性资料表中,栏位 ”mkt” 为 “DIST”即代表目前状态为下市柜公司,我们以此作为资料筛选的依据。

如同之前的步骤对过滤后的股价资料依照股票代码进行分组。
without_dist_coid = comp_data.loc[(comp_data["coid"].isin(inter_coid)) & (comp_data["mkt"] != "DIST")]["coid"].unique()
fltr_price_data = price_data[price_data["coid"].isin(without_dist_coid)]
group = fltr_price_data.groupby("coid")接著一样执行交易策略
principal = 1000000
total_return_2 = 0
df_without_dist = pd.DataFrame(columns = ["日期", "标的", "买入/卖出", "单价", "单位", "剩余现金", "部位"])
for g in group.groups.keys():
reuslt = MA_strategy(group.get_group(g), principal)
total_return_2 += round(reuslt[1], 2)
df = pd.concat([df_without_dist, reuslt[0]], ignore_index=True)return_without_dist = (total_return_2/(1000000*len(group.groups.keys())) - 1) *100
print(f"ROI : {return_without_dist}%")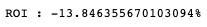
根据计算,剔除下市柜公司后的绩效确实与原本绩效相比更好一点,虽然两者绩效皆为负数,但透过程式实作,我们可以明确发现其中的报酬率存在差异。
一般投资者在进行绩效回测时都会选取在回测时间区段内存活的公司,而忽略了再回测区段中下市柜的公司也应当列入考虑。而存活下来的公司体质在客观层面上就较为优秀,因而使模型产生了较好的投资报酬率,但这样的结果并不准确也并不全面,应当纳入下市柜公司的股价资讯才能更完善的反应当时市场的情形。
幸存者偏差可能导致选股策略的过度优化。如果投资者仅基于过去成功股票的特定因素来选股,而忽略了整体市场的变化和不确定性,则可能无法应对市场的变化,从而影响投资结果。为了避免幸存者偏差对选股的负面影响,投资者应该采取全面的研究方法,包括考虑成功和失败股票的情况。他们应该关注整体市场的趋势、行业的发展、公司的基本面和风险管理等因素,而不仅仅依赖于过去成功股票的表现。此外,投资者应该拥有长期的投资视野,避免过度关注短期的股票表现,并建立自己的投资策略,以符合个人的投资目标和风险承受能力。
温馨提醒,本次策略与标的仅供参考,不代表任何商品或投资上的建议。之后也会介绍使用 TEJ 资料库来建构各式指标,并回测指标绩效,所以欢迎对各种交易回测有兴趣的读者,选购TEJ E-Shop的相关方案,用高品质的资料库,建构出适合自己的交易策略。
