
目录
近年来开始兴起一种投资,叫做环境、社会和治理(ESG)投资,指的是在投资决策时,不再只考虑公司的财务表现,而是额外考虑企业对于环境、社会的影响力,以及公司的行为与准则等。彼此之间不再是抵换关系,而是一种良善的循环,提供公司未来前景的保证,进而为投资者带来丰富的报酬。
因子投资,即试图找出几个关键的影响因素,像是文献常见的规模因子、帐市值比因子、风险因子等等,并预期这些因素能带来超额报酬。因此本周我们以TEJ资料库提供的「员工流动率」当作因子,看看ESG投资的成果吧!
本文使用 Windows OS 并以 Jupyter Notebook 作为编辑器
#功能与视觉化模组 import pandas as pd import numpy as np import plotly.express as px import plotly.graph_objects as go
#TEJ import tejapi tejapi.ApiConfig.api_key = 'Your Key' tejapi.ApiConfig.ignoretz = True
turnover = tejapi.get('TWN/ACSR01A',
paginate = True,
opts = {'columns':['coid','mdate','turn_rate','num_staff']},
chinese_column_name = True)
turnover = turnover[turnover['员工流动率(%)'].isnull() == False]
result = pd.DataFrame() ret_table = pd.DataFrame()
因为员工流动率于年报揭露,为了避免前视偏误,因此本文以年报最晚公布日 (隔年三月底)作为投组建构日,并持有一年。但由于按照2020年报资讯所建立的投组,投组持有期间为 2021–03–31 ~ 2022–03–31,尚未持满一年,因此会排除该年。
date_list = sorted(turnover['年度'].unique())[:-1]
接下来以回圈进行每年报酬率计算,以下内容以第一年 (date = ‘2008–01–01’)的资料处理情形帮助理解,完整回圈请参考完整程式码。
#当期资料选取 data = turnover[turnover['年度'] == date].reset_index(drop=True)
#删除员工人数过少
data = data[data['员工人数'] >= data['员工人数'].quantile(0.1)]
#分群
data['group'] = pd.qcut(data['员工流动率(%)'], q=10,labels = [i for i in range(1,11)])
#储存
result = result.append(data)
首先选取该年资料,并且删除员工人数过低 (小于十分位数)样本。接著使用 函数 pd.qcut(),依员工流动率由小到大形成十个组别,并呈现在group栏,最后储存到 result 里
#投组卖出日期
sell_date = date + pd.Timedelta(days = 365 + 90 + 365)
#投组报酬
port_ret = [date]
根据2008年资讯建立的十个投组,都将于 sell_date (2010–03–31)卖出。而日期 (2008–01–01)与这些投组报酬,将存放于 port_ret 列表
#计算当年各组的投组报酬
for group in range(1,11):
#当年,某组的资料
sub_data = data[data['group'] == group].reset_index(drop=True)
#报酬率捞取
ret = tejapi.get('TWN/APRCD2',
coid = sub_data['公司码'].tolist(),
mdate = {'gte':sell_date - pd.Timedelta(days = 5), 'lte':sell_date},
opts = {'columns':['coid','mdate', 'roi_y']},
paginate = True,
chinese_column_name = True)
#只需要最后一笔
ret = ret.groupby(by='证券代码').last().reset_index()
#投组报酬(%)
port_ret.append(ret['年报酬率 %'].mean())
#表格 ret_table = ret_table.append(pd.DataFrame(data = np.array(port_ret).reshape((1,11)), columns = ['日期'] + [i for i in range(1,11)])).reset_index(drop=True)
接著按照组别由小到大进行回圈。首先先进一步筛选出某组的资料,然后根据这个组别包含的公司、卖出日期捞取年报酬率(%)。这边采用的技巧是先捞取靠近卖出日的年报酬率资料,接著取最靠近卖出日期的年报酬,此即为过去完整一年内的报酬率。最后再取平均值,即为该组投组的等权报酬率,各组都计算完成后,再将列表 port_ret 形成表格后存入 ret_table

其他年份一样重复以上步骤,透过回圈不断地去更新 result 与 ret_table ,最后得到以下结果。
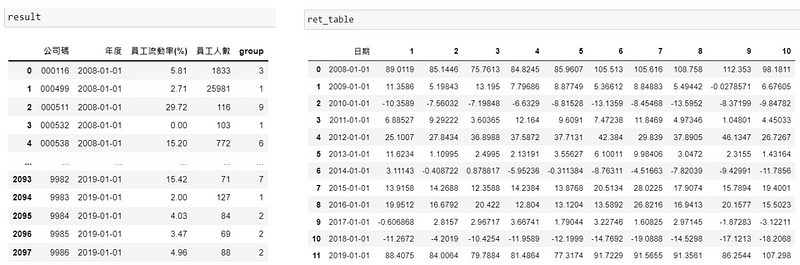
cum_ret = ret_table[[i for i in range(1,11)]].apply(lambda x : (x*0.01 + 1)).cumprod() cum_ret.insert(0, '日期', date_list)
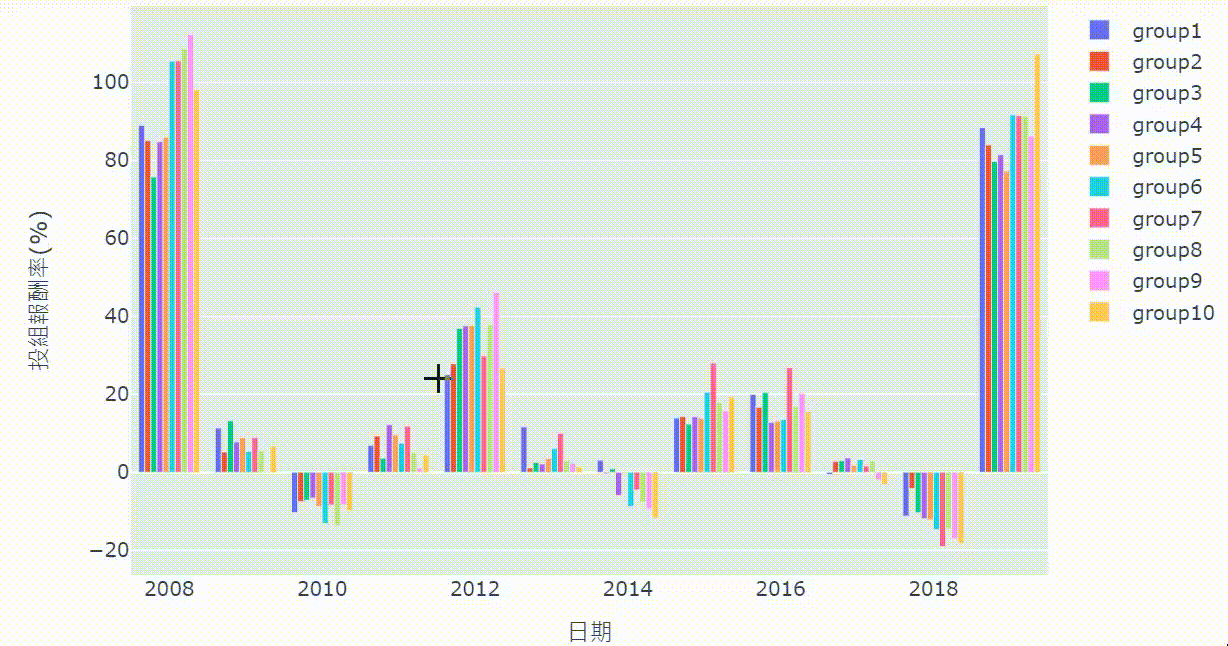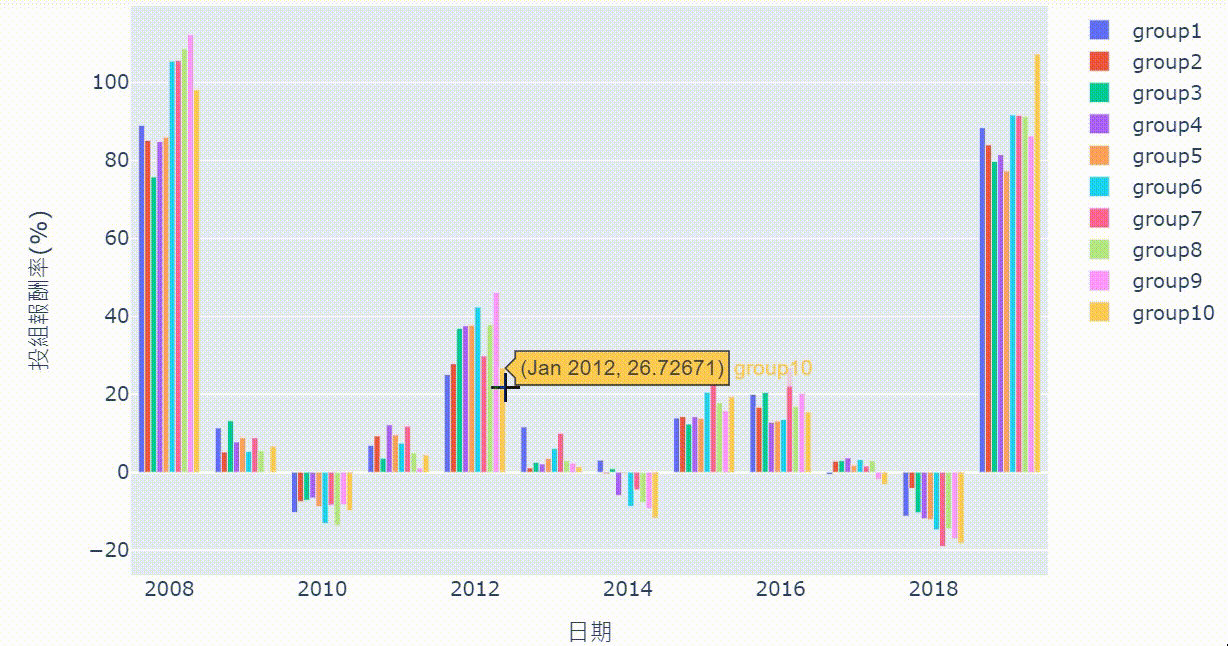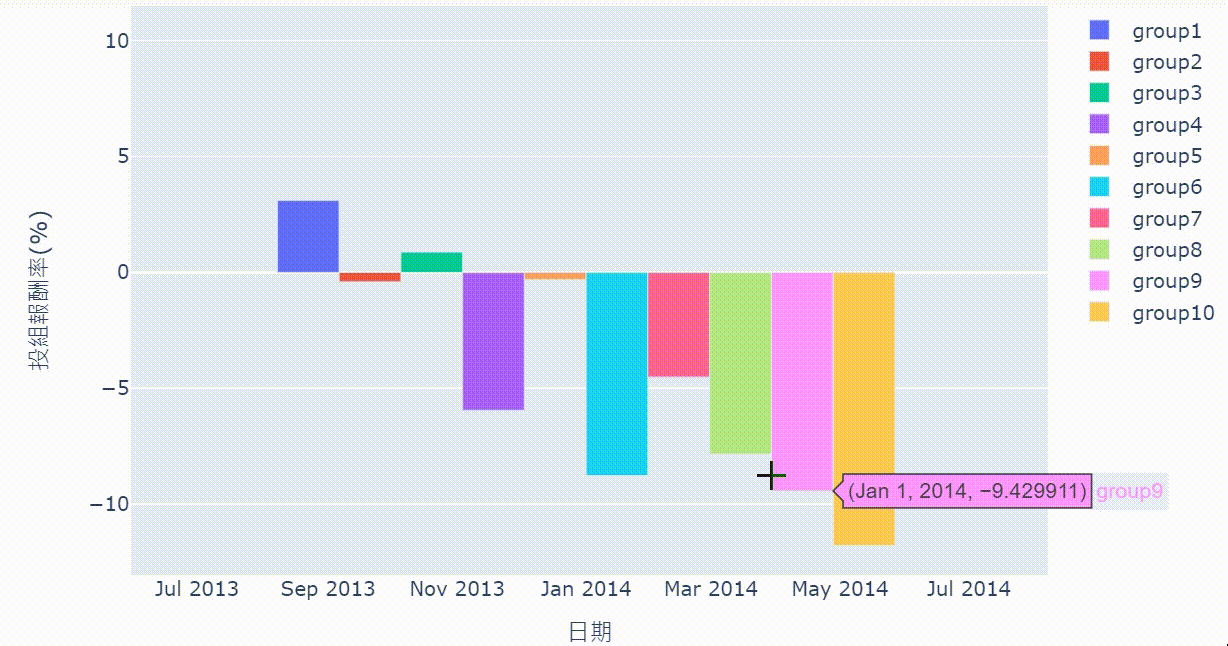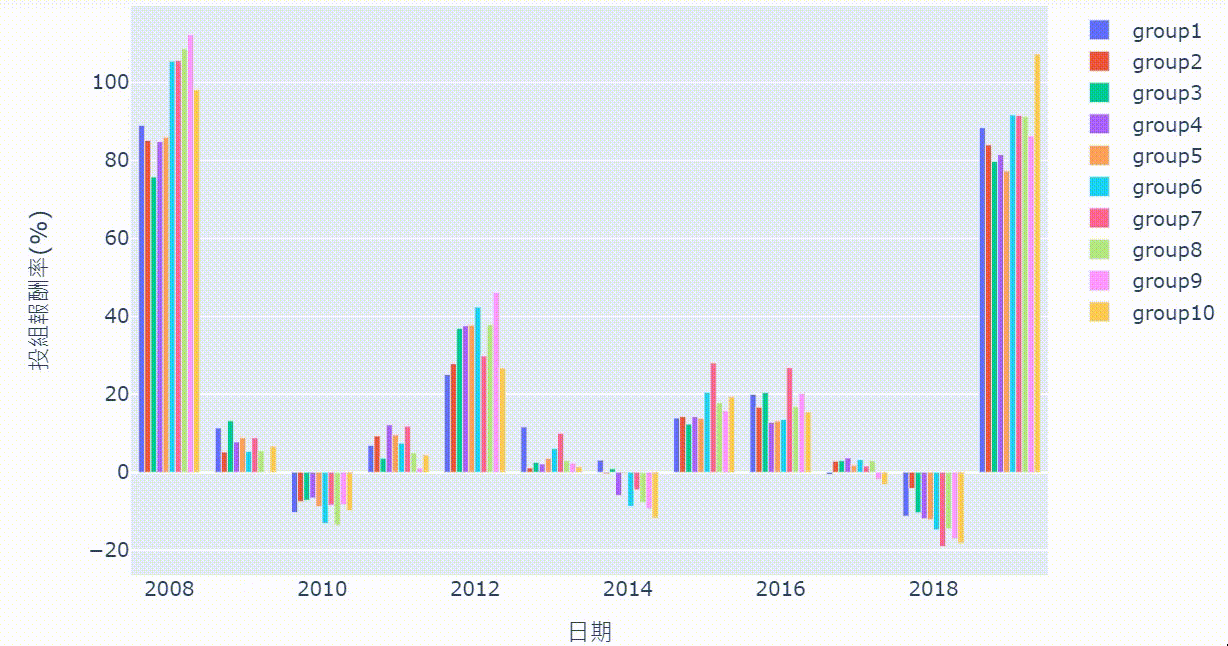
先计算这十组投组的累积报酬率,再补上日期,最后再画出
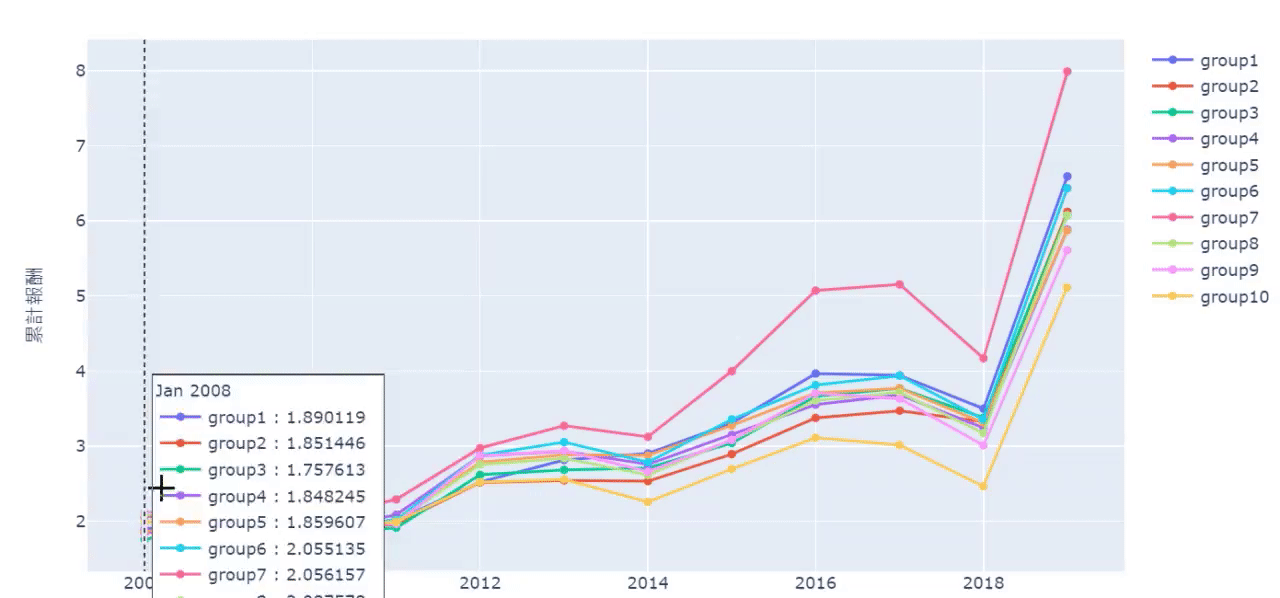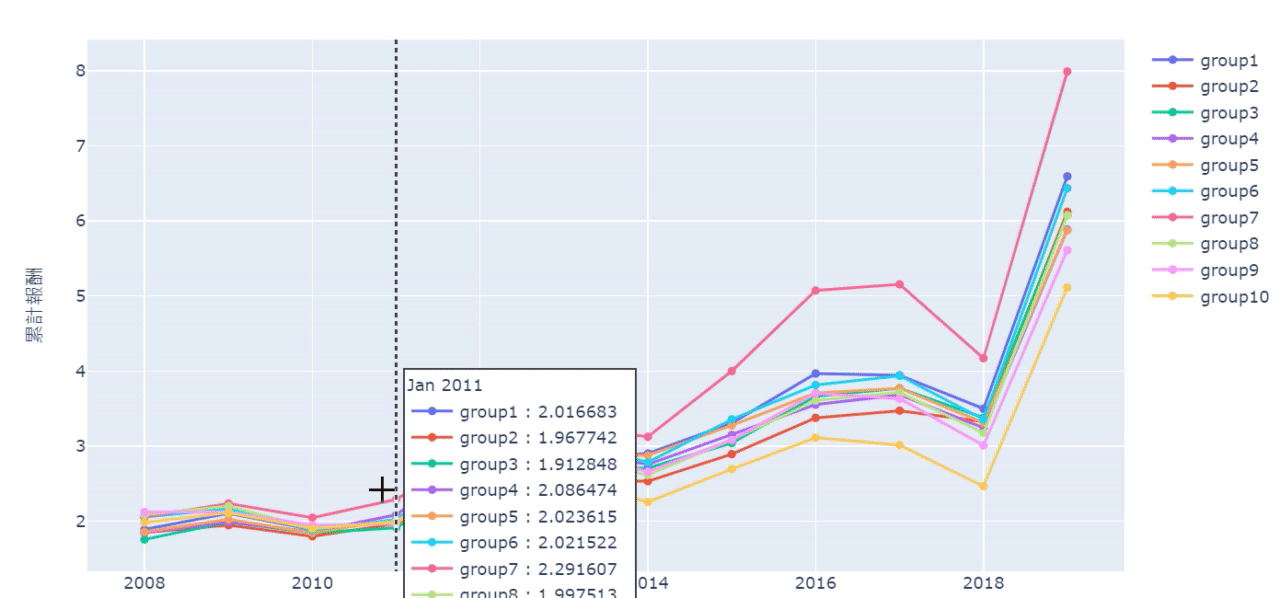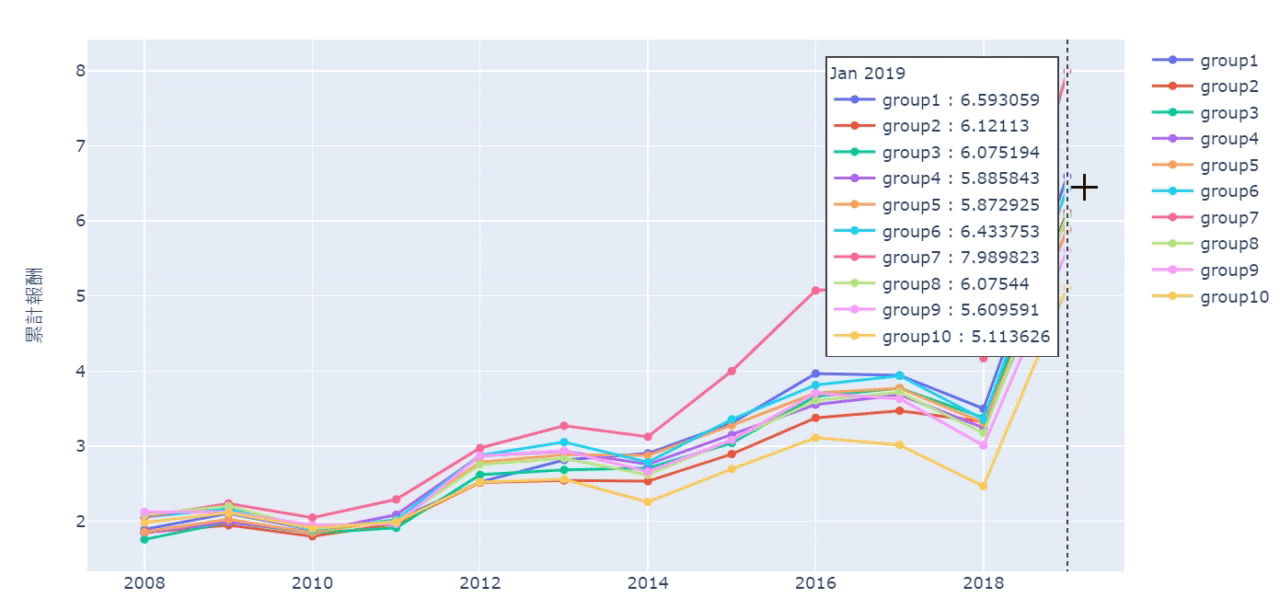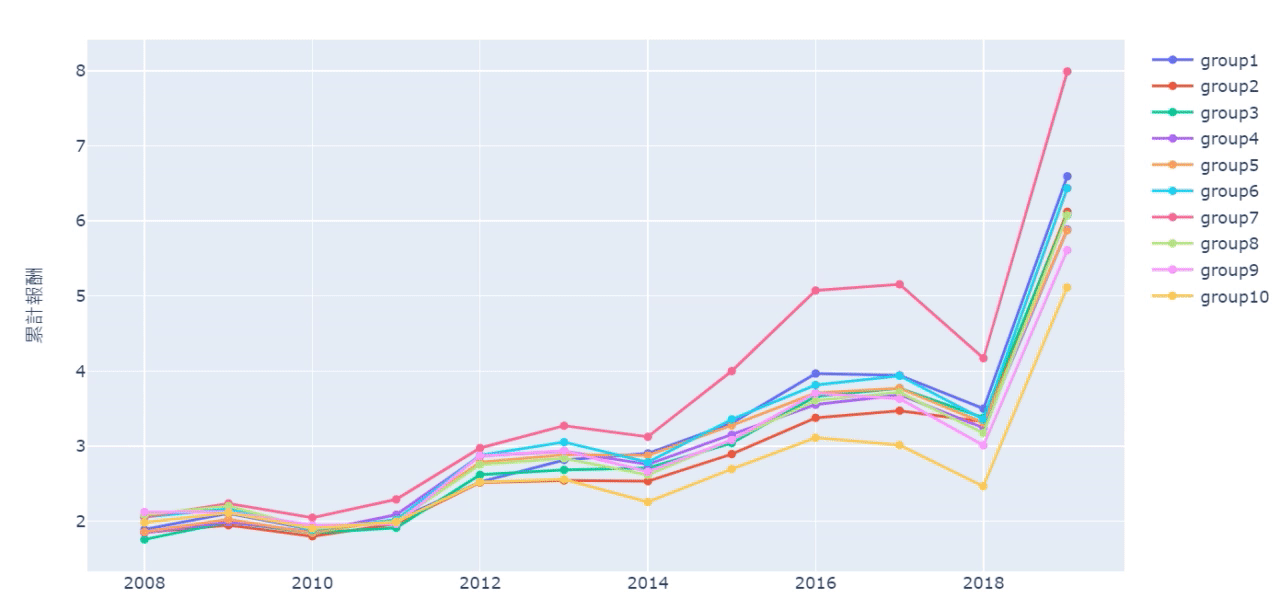
sharpe_list = []
for i in range(1,11):
#年化报酬率
cagr = (cum_ret[i].values[-1]**(1/len(cum_ret)) - 1)*100
#年化标准差
std = ret_table[i].std()
#更新list
sharpe_list.append(i)
sharpe_list.append((cagr-1)/std)
#形成表格 sharpe = pd.DataFrame(np.array(sharpe_list).reshape((10,2)), columns = ["group","夏普比率(%)"])
先计算出夏普比率,再画出
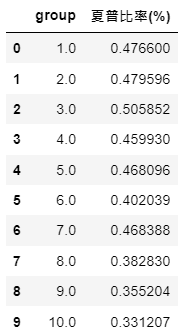
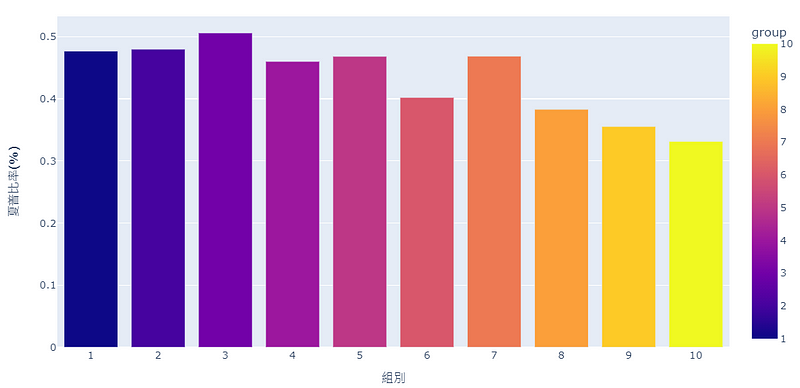
从累积报酬图与夏普值可以发现,员工流动率最高的第十组表现最差,即使其在部分年间有好的报酬表现。但这并不意味著员工流动率低,公司的表现就一定会比较好,例如从累积报酬图来看,第七组是表现最好的,或许这也代表保持一定的员工流动,反而能维持公司的竞争力与创新意识。
整体而言,在市场表现差时,员工流动率较差的公司损失幅度较大,代表ESG因子某种程度提供一定的下行风险保护。如果读者对于其他ESG资料有兴趣,欢迎到 TEJ E-Shop 选择最适的方案,找出更多创造超额报酬的因子!
